
Indice articolo
La generazione dei log è una scelta indispensabile per ogni tipo di applicazione, strumento con il quale lo sviluppatore o l’analista può capire se il flusso di lavoro sta andando come previsto oppure no.
Ancor più efficace è, se i log sono stati scritti correttamente, l’identificazione quasi immediata del motivo per cui il sistema non si comporta come si vorrebbe e soprattutto il punto esatto su cui intervenire.
E quindi di fondamentale importanza saperli leggere e sopratutto “farseli propri”. Vediamo assieme come possiamo fare per estrarre le informazioni di interesse con il minimo sforzo!
Artifact
Quante volte ci sarà capitato di accorgerci che l’applicazione che stiamo usando non sta funzionando nel modo in cui saremmo aspettati o magari non sta funzionando affatto. Magari per uno sbaglio del programmatore o forse per una svista del sistemista o guarda caso, magari la scelta di installarlo su un pc vecchio di 10 anni non è stata delle più brillanti; sta di fatto che questo ha portato ad avere una situazione di instabilità che all’apparenza sembra priva di senso. Come possiamo quindi CAPIRE il perchè certe cose succedono e certe altre no? Solo e solamente la parte dei log può saperlo.
Notare che non ho utilizzato a caso la frase “solo e solamente la parte dei log può saperlo” proprio perchè le informaziono risiedono lì dentro e sta a noi cercarle. Se dovessi usare una metafora, paragonerei la situazione corrente al possedere un cassetto pieno di carte e/o lettere, ed affermare che in mezzo alle scartoffie si nasconda una multa. Sta di fatto che se non avvio una fase di controllo, di ricerca ed estrazione, non sarò mai in grado di provarlo con certezza.
Magari quindi la multa è veramente nel cassetto, ma se non attuo una metodologia di recupero, il mio lavoro sarà quello di far passare uno a uno ogni pezzo di carta fino a quello corretto.
Prima di iniziare però è giusto dare una panoramica di come vengono generati e che “forma” hanno i log in SmeUP, per fare questo rimando agli articoli :
Come customizzare i log?
Perchè customizzare i log ci si starà chiedendo?
Beh semplicemente perchè customizzare significa dare una propria impronta di lettura (e quindi di significato) ad una serie di informazioni che per qualcun’altro potrebbero risultare inutili e/o viceversa.
Perchè riuscire a capire la metodologia per il recupero di informazioni è essenziale per risolvere situazioni in poco tempo e in modo altrettanto “agile“.
Rifacendoci alla metafora precedente del cassetto con le scartoffie, è utile pensare ogni utente che ne osserverà l’interno, potrà recepire differenti informazioni in base alla ricerca effettuata, potrà infatti estrarre informazioni per lui fondamentali, ma che un’altra persona potrebbe reputare come “spazzatura“.
Come fare quindi questo tipo di cernita? Beh è uno strumento che utilizziamo inconsciamente nella vita di tutti i giorni, ma se dovessimo applicarlo a questo caso specifico bisognerebbe iniziare con il porsi alcune domande prima di iniziare la ricerca (eccone un esempio):
- Siamo sicuri che la multa si trovi in questo cassetto? Ovvero: è giusto cercare questo tipo di informazione all’interno di questo log?
- Come sono fatte le multe? Ovvero: c’è qualcosa che identifica in modo più o meno univoco l’informazione che voglio estrarre per aumentare il mio fattore di ricerca?
- Come posso velocizzare la ricerca di una multa sapendo come è fatta? Ovvero: c’è un modo per separare in modo agile l’informazione dal resto del contenuto (detto rumore) sapendo rispondere alla domanda precedente?
- E’ l’informazione che stavo cercando? Ovvero: fase di affinamento in cui ci si fanno altre domande più specifiche per affinare il campione estratto.
- …
Potrebbero essercene molte altre e più domande ci si pone e si arriva ad una risposta e più la nostra ricerca sarà mirata e veloce.
Ritornando al nostro caso di esempio potremmo dire:
- sì, la multa si trova nel primo cassetto perchè è quello in cui ci finisce tutta la posta una volta che la ritiro dalla cassetta delle lettere.
- le multe solitamente sono in una busta verde
- al posto di controllare una carta per volta, potrei estrarre tutte le lettere, metterle su un tavolo, sparpagliarle e a colpo d’occhio visualizzare tutte quelle verdi
- tra le 4 che ho trovato, quale è quella che scade prima
- …
Con queste semplici informazioni saprò con certezza che riuscirò a focalizzarmi solo sui dati che mi interessano (le buste verdi) nel posto corretto (primo cassetto) e con la massima velocità (sparpagliandole e non esaminandole una ad una) e ancor di più riuscirò a togliere tutto il “rumore” che per me non ha interesse (qualsiasi cosa che non sia verde e che non stia nel primo cassetto). Si passa poi ad una fase di affinamento che andrà a selezionare solo e solamente ciò che si vuole.
Per fare questo ci vengono in soccorso molte risorse.
Strumenti per customizzare i log
Unix like
Per sistemi Unix like potrebbe essere utile utilizzare strumenti che, anche a fronte di una mole di log molto ampia, possono produrre un risultato in pochi milesimi di secondo. In questo caso ci si potrebbe affidare a pipe di istruzioni di:
– cat : visualizzatore di file
– less : altro visualizzatore di file
– grep : strumento usato per la ricerca di stringhe (o regex) in file o strutture ad albero
– egrep : stesso strumento precedente, ma con un’estensione nell’utilizzo dei pattern di regex per la ricerca
– cut : strumento per eliminare righe, colonne ecc…
– awk : strumento complesso per estrazione di dati
– ….
Vedremo comunque di seguito come usarle.
Windows like
Per sistemi Windows like potrebbe essere utile l’utilizzo di più software in base al risultato voluto.
In prima battuta potrebbe essere comodo per esempio usare Notepad++. Per i più è solamente uno strumento di lettura di files, ma invece mette a disposizione molte feature più o meno nascoste.
Con esso è facile avere a colpo d’occhio la stessa cosa che avremmo utilizzando grep o egrep semplicemente facendo una ricerca.
Infatti basterà per esempio aprire il file di log desiderato e cliccare “CTRL + F” sulla tastiera per avere a disposizione la ricerca all’interno del file
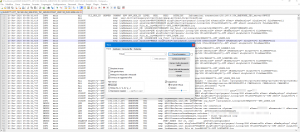
Scegliamo quindi per esempio di cercare tutte le chiamate di ping dovremo cercare “F(INT;JA_00_24;XML.PING)”, ma al posto di fare una ricerca normale, clicchiamo sul pulsante “Trova tutto nel documento corrente” .
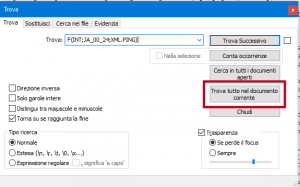
Così facendo verrà a visualizzarsi nella parte inferiore dello schermo un raggruppamento di tutte e sole le righe conenenti la “frase” cercata come è possibile vedere qua sotto:
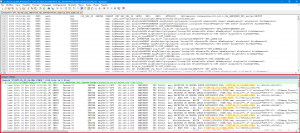
Con questo filtro è possibile giocare anche con le regex (pulsante regex attivato) o tramite i plugin scaricabili ed installabili è facile customizzare i log a proprio piacimento.
Un esempio reale
In laboratorio in questo periodo è stato necessario analizzare per esempio i log generati dallo smartkit-fe per avere una migliore visione di una situazione di errata gestione di processo dello stesso.
Per prima cosa è stata fatta un’analisi, ovvero ci si è chiesti quali erano i parametri che si volevano osservare (o che ci si aspettava di trovare) dai log.
Siccome una parte del progetto verteva sull’individuazione del numero di chiamate A38, la loro sequenzialità e le chiamate in errore, ci si è focalizzati quindi sull’estrazione delle chiamate al servizio JA_00_52 (che è quello che provvede a far arrivare al provider una chiamata del LOA38).
Per fare questo è bastato un semplicissimo comando:
$ egrep -i "F\(XML;JA_00_52;SND.PAY\)" ./FileDiLog.log
In questo modo vengono visualizzate a video tutte le linee in cui compare la scritta “F(XML;JA_00_52;SND.PAY)” nel file “FileDiLog.log”.
Ora, dato che di tutte questa sfilza di righe a noi interessava solo la prima riga di ogni chiamata si sono isolate inserendo una maggior specificità della ricerca ed eliminando il resto del rumore lanciando il comando:
$ egrep -i "Wait=300 F\(XML;JA_00_52;SND.PAY\)" ./FileDiLog.log
La situazione è stata più o meno la seguente
Si è poi deciso di salvare queste informazioni in un file per poi analizzarle con più facilità. Per fare ciò è bastato redirigere l’output del comando in un file chiamato “customLogSequentiallyCall.log”:
$ egrep -i "Wait=300 F\(XML;JA_00_52;SND.PAY\)" ./FileDiLog.log > customLogSequentiallyCall.log
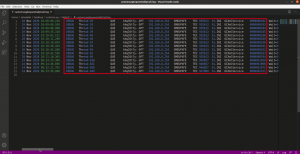
Si è poi passati ad una fase di affinamento dei dati.
Dato che questo doveva essere il file per la sequenzialità delle chiamate, si è scelto di eliminare tutte le colonne inutili al fine e di lasciare solo quelle dell’ora e quelle del tipo di chiamata, è stato aggiunto in cascata al comando di egrep anche quello di awk, il quale estrae solo le colonne 3,16,17 e 21:
$ egrep -i "Wait=300 F\(XML;JA_00_52;SND.PAY\)" ./FileDiLog.log | awk '{print $4" "$17" "$21 }' > customLogSequentiallyCall.log
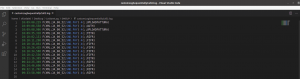
Il nostro scopo era finito, ma per completezza, complicando leggeremente il comando di awk si ha la possibilità di inserire più logica sulle colonne con il seguente risultato:
$ egrep -i "Wait=300 F\(XML;JA_00_52;SND.PAY\)" ./FileDiLog.log | awk '{for(i=1;i<=4;i++){out=out" "$i}; for(i=16;i<=NF;i++){out=out" "$i}; print $out}' > customLogSequentiallyCall.log
In cui è stato detto a awk di prendere l’output prodotto da egrep e di visualizzare solo e solamente le colonne 1,2,3,4 e tutte quelle successive alla 16. Il risultato è il seguente:
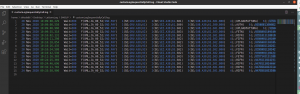
Come abbiamo visto con 2 istruzioni è stato possibile estrarre e ridurre in tempo 0 le informazioni contenute nel log dello smartkit.
Altra situazione identica è stata utilizzata per visualizzare gli errori delle chiamate.
Sapendo che gli errori si trovavano sulla riga con “Status: *ERROR” è banale capire che tramite la stessa identica istruzione di prima è possibile visualizzare anche le chiamate in errore:
$ egrep -i "Wait=300 F\(XML;JA_00_52;SND.PAY\)|Status: \*ERROR" ./FileDiLog.log | awk '{for(i=1;i<=4;i++){out=out" "$i}; for(i=16;i<=NF;i++){out=out" "$i}; print $out}' > customLogSequentiallyCallWithError.log
Il risultato apprezzabile è il seguente:
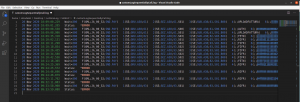
Come è possibile vedere massimo risultato con il minimo sforzo!