
Indice articolo
Lo scopo di questo articolo è quello di mostrare il lavoro fatto per permettere l’accesso web a Smeup ERP tramite l’utilizzo del protocollo HTTP. Sono stati sviluppati due progetti riferiti alle seguenti tecnologie: REST API e GraphQL. Questo articolo sarà quindi suddiviso in due parti per mostrare la loro implementazione.
Cos’è GraphQL
GraphQL può essere considerato come l’evoluzione del REST API e di conseguenza anche una sua alternativa.
E’ un linguaggio che permette all’applicazione di frontend (client) di comunicare con l’applicazione di backend (server). Esattamente come succede per REST API, le due applicazioni comunicano tra loro, quello che cambia è la modalità con cui viene fatto.
Nella prima parte di questo articolo, abbiamo visto il numero di endpoint che servono in un’applicazione REST API per far comunicare il client con il server. In questa seconda parte riguardante GraphQL possiamo partire dicendo che serve UN SOLO ENDPOINT.
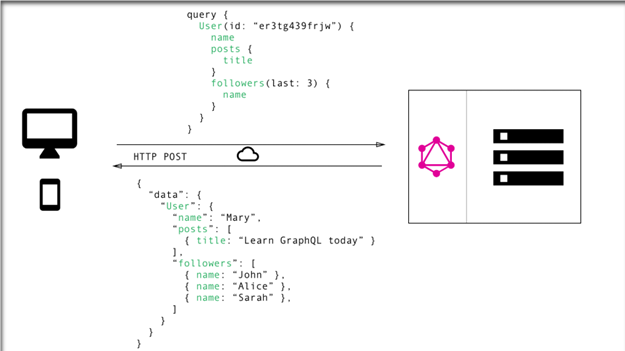
Con questo endpoint si invia una richiesta in formato JSON nella quale vengono specificate non solo le operazioni da fare, ma anche le entità ed i relativi campi su cui operare. La query include i requisiti concreti dei dati. Il server risponde quindi con un oggetto JSON in cui questi requisiti sono soddisfatti.
Il client può specificare esattamente i dati necessari in una query. Si noti che la struttura della risposta del server segue esattamente la struttura nidificata definita nella query.
Questa struttura evita diversi problemi rispetto a REST API ed introduce invece molti vantaggi:
- Overfetching: si evita di scaricare di dati superflui
- Underfetching: si evita di dover usare altri endpoint per leggere dati collegati alle chiamate precedenti
- Iterazioni rapide frontend: il client è indipendente dal server perché conosce esattamente i dati che ha a disposizione
- Migliori analisi del backend: è possibile storicizzare le richieste ed eseguire analisi su di esse per capire quali sono i dati richiesti più frequentemente.
- SDL: lo Schema Definition Language è un contratto tra client e server su cui vi sono scritte sia le entità disponibili che i relativi campi. Una volta stabilito, questo contratto mantiene i team sia di frontend sia di backend indipendenti.
Struttura di un’applicazione GraphQL
Per implementare GraphQL, si deve intervenire sia nell’applicazione del backend (server) che in quella del frontend (client).
Sul server si deve:
- Importare la libreria di GraphQL, che permette di interpretare le richieste del client.
- Implementare tutti i metodi che devono essere poi mappati nello schema di GraphQL. Ad esempio, nella figura seguente, si vede un tipo “Query” che fa riferimento ad un metodo “allPersons”. Questo metodo si riferisce ad una funzione del backend che dovrà restituire i dati. I dati in questo caso, si riferiscono ad un’entità con il nome “Person”, che dovrà essere definita nel backend. In pratica, ogni cosa che viene definita nello schema deve essere implementata nel backend.
Sul client si deve:
- Importare la libreria del client di GraphQL (es. Apollo per Angular) che gli permette di importare lo schema del server ed inviargli le query che servono.
Ci sono diverse implementazioni sia server che client a seconda del linguaggio di programmazione utilizzato.

Lo schema è la cosa più importante su GraphQL. Specifica le capacità dell’API e definisce come i client possono richiedere i dati. Viene spesso visto come un contratto tra il server e il client. Nello schema ci sono 3 tipi di root: Query, Mutation e Subscription.
Query
Quando si lavora con le API REST, i dati vengono restituiti da endpoint specifici. Ogni endpoint ha una struttura chiaramente definita delle informazioni che restituisce. Ciò significa che i requisiti di dati di un client sono effettivamente codificati nell’URL a cui si connette.
L’approccio adottato in GraphQL è radicalmente diverso. Invece di avere più endpoint che restituiscono strutture di dati fisse, le API GraphQL in genere espongono un singolo endpoint. Questo funziona perché la struttura dei dati restituiti non è fissa. Al contrario, è completamente flessibile e consente al client di decidere quali dati sono effettivamente necessari.
Ciò significa che il client deve inviare più informazioni al server per esprimere le sue esigenze in termini di dati: queste informazioni sono chiamate query.
Mutation
Oltre a richiedere informazioni da un server, la maggior parte delle applicazioni necessita anche di un modo per apportare modifiche ai dati attualmente memorizzati nel back-end. Con GraphQL, queste modifiche vengono apportate utilizzando le cosiddette mutations. Ci sono tre tipi di mutation: creazione, modifica ed eliminazione di dati esistenti.
Subscriptions
Un altro requisito importante per molte applicazioni di oggi è avere una connessione in tempo reale al server per essere immediatamente informati su eventi importanti. Per questo caso d’uso, GraphQL offre il concetto di subscriptions.
Quando un client si iscrive a un evento, avvierà e manterrà una connessione costante al server. Ogni volta che si verifica effettivamente quel particolare evento, il server invia i dati corrispondenti al client. A differenza di query e mutations che seguono un tipico “ciclo di richiesta-risposta”, le sottoscrizioni rappresentano un flusso di dati inviati al client.
Tipi Personalizzati
GrapqhQL richiede che la definizione dei dati (nell’immagine in alto sarebbero: Person e Post) sia presente nello schema.
Resolvers
GraphQL permette di stabilire le relazioni che ci sono tra le entità. Questo è un aspetto fondamentale, perché tramite queste relazioni è possibile poi eseguire un unica query per recuperare informazioni da entità diverse, ma collegate tra loro logicamente. Ad esempio, si può richiedere un TODO (H3£TDO) e le informazioni del progetto collegato (TACPG), in un’unica query. Nel REST API, per fare la stessa cosa, servirebbero due richieste.
Smeup GraphQL
Come detto precedentemente ci sono diverse librerie di GraphQL. In Smeup, è stata utilizzata la libreria per Java per la parte server che è stata implementata in un progetto a parte. Mentre non è stato possibile implementare alcun client perché WebUp (frontend di Smeup) non è un client puro su Javascript. Le pagine web ed i relativi javascript di WebUp vengono iniettati dal backend. Questa cosa non ha permesso di gestire GraphQL in modo canonico.
A scopo di proof of concept, si e’ quindi utilizzato un client chiamato GraphiQL che viene fornito insieme alla libreria server per fare i test. In pratica, GraphiQL è un’interfaccia web che simula un client.
Inoltre, come detto anche nella prima parte di questo articolo, nel caso di Smeup il database non è statico . Le entità non hanno dei campi fissi ma variabili e questo va in contrasto con la necessità di GraphQL di avere uno schema fortemente tipizzato. Questo ci ha costretto a creare, come proof of concept, uno schema su GraphQL per le seguenti entità:
- items (ARART)
- todo (H3£TDO)
- collaborators (CNCOL)
- customers (CNCLI)
- projects (TACPG)
Abbiamo mappato alcuni nomi di campi dal nome OAV ad un nome «parlante» che sono visibili durante l’utilizzo delle query esattamente come è stato fatto per le REST API.
Di seguito vengono riportati alcuni esempi di query eseguite con GraphiQL.
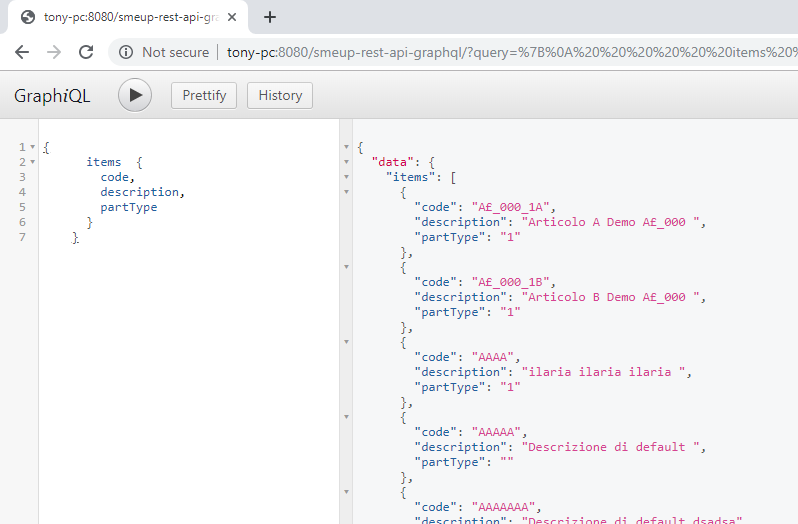
Selezione di tutti gli articoli (items):
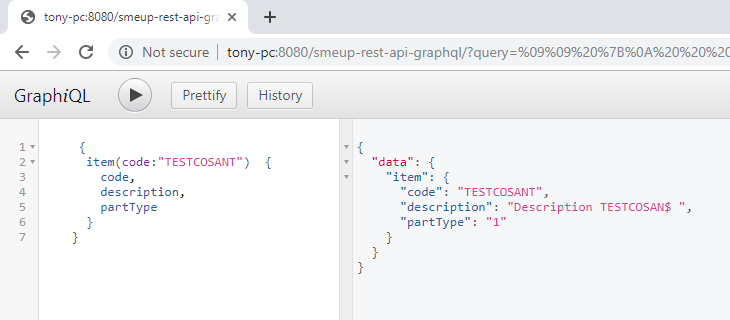
Query di un singolo articolo (item):
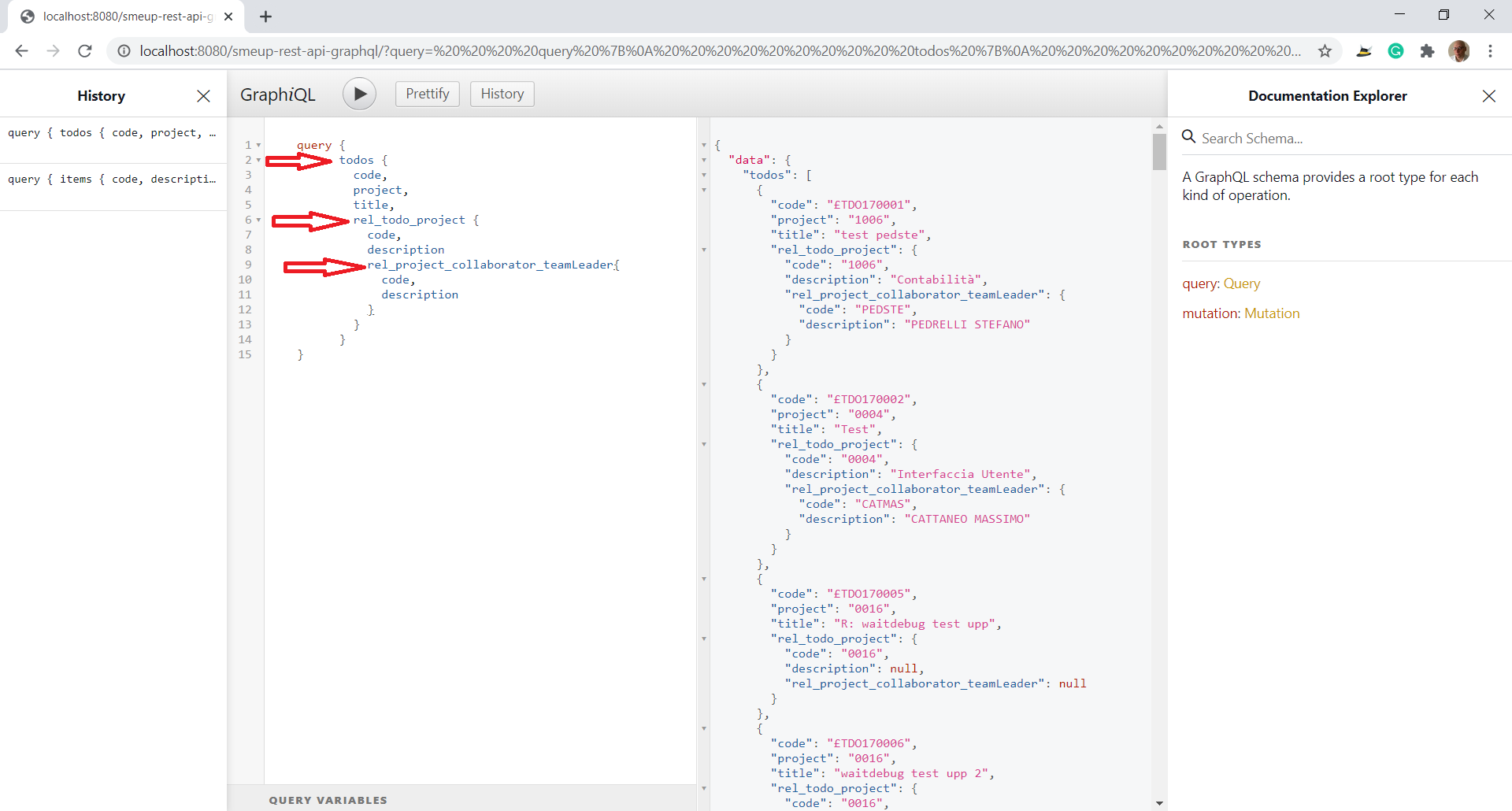
Segue la selezione di tutti i TODO. Per ogni TODO, vengono inoltre richiesti i dati del progetto e, all’interno del progetto, vengono richiesti anche i dati del team leader. Quest’immagine riassume le potenzialità ed i vantaggi che potete leggere in dettaglio nel paragrafo successivo:
Vantaggi di Smeup GraphQL
Oltre ai vantaggi che derivano nell’utilizzare una tecnologia standard come HTTP che sono già stati citati nella prima parte di questo articolo, con GraphQL si aggiungono altri fattori che lo rendono uno strumento ideale nelle applicazioni frontend:
Name mapping
Come per il REST API, anche in GraphQL abbiamo mappato i campi con nomi parlanti per rendere la vita più semplice a chi deve interrogare il database di Smeup.
Operazioni equivalenti su REST API
Quando si richiedono dati nidificati, viene eseguita una sola query anziché n (dove n sta per il numero delle entità coinvolte).
Response size
Nelle query di GraphQL è possibile selezionare i campi da ricevere. Questo fattore di enorme rilevanza, diminusce il peso dell’applicazione sulla rete.
Tempi di esecuzione
Con quanto detto precedentemente, diventa ovvio ed implicito il miglioramento delle prestazioni causato dal minor numero di chiamate e dalla dimensione inferiore delle risposte. Tutto questo conduce ad una maggiore velocità di risposta.
Statistiche di GraphQL
Nel backend è possibile attivare il monitoraggio delle statistiche delle richieste. Anche questo elemento è importante, perché permette di eseguire delle analisi sullo storico delle chiamate per capire quali sono i dati più richiesti ed eventualmente migliorare le relazioni o i modelli dei dati.
Conclusioni
Abbiamo visto come è possibile ottimizzare ed accellerare l’accesso dei dati di Smeup. GraphQL è uno strumento molto potente che rivoluziona l’architettura del REST API. Come detto nella prima parte dell’articolo, serviranno delle modifiche molto importanti sia nel backend che in WebUp per usufruire appieno delle potenzialità di GraphQL.