
La schedulazione a capacità infinita (d’ora in poi SCI) è una modalità di datazione approssimativa di un ciclo (sia di un articolo sia di un ordine, pianificato o rilasciato), con lo scopo di determinarne l’inizio o la fine (tramite la datazione delle singole fasi), e di valutare il carico delle varie risorse nel tempo, senza ricorrere a strumenti più complessi ma più realistici, quali la schedulazione a capacità finita.
Cominciamo con lo sgombrare il termine da equivoci: di infinito non c’è niente. Più corretto sarebbe utilizzare l’altro termine (talvolta presente in letteratura) di “schedulazione a capacità illimitata”, nel senso che la fabbrica ha sempre le risorse che servono per la realizzazione di tutti i lavori (non ha limiti nella capacità che può mettere a disposizione).
Descrizione del metodo
La SCI si basa sull’assunto che il job da schedulare sia l’unico ad utilizzare la capacità delle risorse necessarie alla sua realizzazione, indipendentemente da tutti gli altri job che impiegano le stesse risorse.
Ad esempio, se una fase impiega 10 minuti al pezzo, e si deve eseguire un job di 36 pezzi, (per un totale di 360 minuti, pari a 6 ore), su di una risorsa aperta dalle ore 8 alle 12 di ogni giorno (per un totale di 4 ore), se la fase inizia al giorno X, essa verrà schedulata dalle ore 8 del giorno X alle ore 10 del giorno X+1, come risulta dal seguente prospetto:
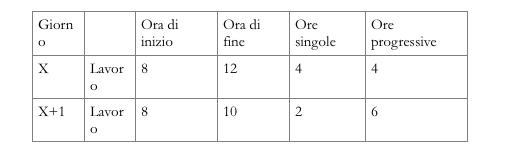
Qualora si schedulasse successivamente un’altra fase (di un altro job) con esattamente gli stessi dati di input, essa verrebbe posizionata nello stesso intervallo di tempo.
E’ chiaro che questo assunto porta a sovraccaricare la risorsa oltre la sua disponibilità, con l’effetto di datare in modo irrealistico le fasi, e quindi la fine dell’intero ciclo. Nella realtà, oltre al tempo di lavorazione, nell’esecuzione del ciclo vi è un tempo di coda presso le varie risorse (l’attesa fino a che la risorsa diventi disponibile).
La schedulazione a capacità finita determina esattamente il tempo di attesa di ogni fase, sequenziando le attività da eseguire.
Nella SCI, invece, si assegna ad ogni risorsa, in base a rilevazioni effettuate, un tempo di coda medio, che si aggiunge al tempo di lavorazione, per la datazione dell’inizio della fase (non per il carico).
L’introduzione delle code infatti non fa aumentare il carico, ma lo sposta nel tempo.
Se, nell’esempio precedente, per la risorsa sono previste 7 ore di coda, la fase sarà datata dalle ore 11 del giorno X+1 alle ore 9 del giorno X+3, come risulta dal seguente prospetto.
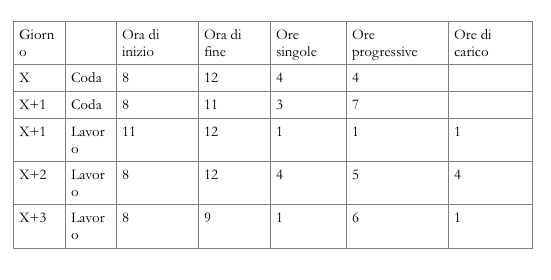
In questo modo non si ottiene l’effetto di datare più esattamente le singole fasi (che non è lo scopo della SCI), dato che la coda si applica a tutte le fasi (che quindi resterebbero comunque contemporanee se lo erano prima di applicare la coda) ma di ottenere una data di completamento dell’intero ciclo più realistica, ed inoltre di avere un carico meno approssimato su ogni singola risorsa. Questo secondo miglioramento aumenta all’aumentare della lunghezza del periodo su cui si determina il carico: se esso è giornaliero, probabilmente vi saranno comunque sovra e sottocarichi irrealistici, se invece lo si considererà settimanale, i picchi si medieranno ed il valore del carico diventerà più affidabile. Oltretutto, all’aumentare del periodo di analisi, risulta sempre meno importante l’affidabilità del valore della coda. Se si determina il carico mensile, ad esempio, è del tutto inutile utilizzare i tempi di coda, che presumibilmente non farebbero che spostare i carichi all’interno del periodo, senza alcun effetto sul risultato globale.
La SCI può essere eseguita in due modalità:
- al più presto, partendo dalla data inizio e posizionando, in avanti, le fasi a partire dalla prima. In questo modo si confronta la data di fine schedulata con la data fine richiesta: si ottiene l’informazione di quando si finisce rispetto al previsto se si comincia all’inizio previsto, in modo da valutare se, approssimativamente, verrà rispettata la consegna o si andrà in ritardo. I precedenti prospetti sono stati ottenuti con questo metodo.
- al più tardi: dalla data fine, posizionando le fasi dall’ultima all’indietro. In questo modo si confronta la data inizio schedulata con la data inizio richiesta: si ottiene l’informazione di quando si deve iniziare per finire alla data prevista. Se l’inizio calcolato è minore della data di inizio richiesta, vuol dire che si dovrà partire in anticipo, se addirittura sfonda nel passato vuol dire che si andrà sicuramente in ritardo.
L’esempio precedente, con schedulazione al più tardi a partire dal giorno X, produce il seguente risultato:
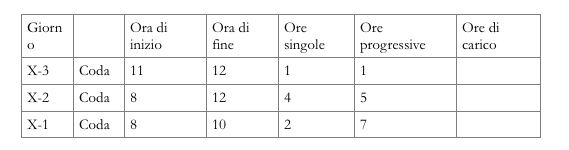
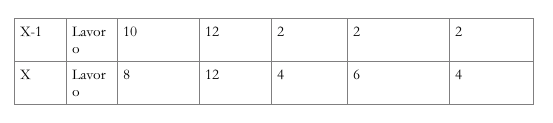
Questi risultati, tuttavia, non vanno presi a occhi chiusi: la correttezza dell’algoritmo non recupera l’approssimazione contenuta nei dati di input (l’entità delle code). È un errore in cui spesso si incorre: intimoriti dai calcoli e dalle formule, si trascura il fatto che essi sono soltanto dei trituratori: se il caffè è di scarsa qualità è improbabile che, macinato, diventi più buono, anche se può sempre peggiorare.
Utilizzo della SCI all’interno della schedulazione a capacità finita
Nella schedulazione a capacità finita non devono essere utilizzate le code teoriche della SCI, in quanto il suo compito è di determinare l’andamento delle code effettive che, ad ogni istante di tempo, sono presenti davanti ad ogni risorsa.
All’interno di questo metodo, se vi sono risorse che si prevede che non saranno mai sovraccariche, vale a dire che non si formerà mai una coda davanti a loro, è possibile trattarle a capacità infinita. Quando è stata schedulata la fase precedente, ed è quindi noto l’istante al più presto della fase da trattare a SCI, si avanza unicamente del tempo necessario ad eseguirla, e si rende pronta la fase successiva al suo istante di fine. In questo modo si riduce il tempo di elaborazione. Va controllato comunque che non si verifichino eccessive contemporaneità tra le fasi elaborate da questa risorsa, vale a dire che, almeno nella maggioranza dei casi, l’ipotesi di assenza di code sia confermata.