
Indice articolo
Abbiamo rilasciato un sacco di novità relative al Json, chiamo il tutto in modo roboante Json.UP, tenetevi forte che state per essere sparati in un nuovo mondo, dove qualsiasi cosa è già integrata in Sme.UP.
Cosa è il Json
Per chi non lo sapesse, si tratta di un formato di interscambio dati che ha già preso piede nel mondo dell’integrazione di applicazioni. In rete si trovano già numerosi webservice che lo utilizzano, in primis le API di google. Ma non è solo questo: può essere considerato anche un formato di memorizzazione di dati e strutturata, dove la gerarchia delle informazioni, organizzata ad oggetti, non ha alcun limite. Infine, ma non per ultimo, rispetto all’xml ha un efficace concetto di Array.
Cosa abbiamo fatto
I nuovi rilasci comprendono il reperimento di Json da web service, oltre che ovviamente da file, una navigazione estremamente intuitiva, una API di alto livello che ne rende semplicissimo il reperimento dei dati e delle API di basso livello, per necessità elaborative complesse.
Prima di vedere ciò che abbiamo rilasciato è bene sapere che il tutto si appoggia a delle procedure specifiche per il Json rilasciate da Scott Klement per la nostra piattaforma. Si tratta di un parser di basso livello a cui ci siamo interfacciati per rendere facile la lettura dei dati di un Json, pertanto per utilizzare tutto ciò è necessario avere in linea la libreria distribuita YAJLLIB che le contiene (requisito di sistema operativo: V6R1). Per ciò che abbiamo rilasciato, installabile dalla release Sme.UP V3R2, è possibile scaricare il pacchetto di distribuzione SDST_LO004. Entrambi sono già disponibili in area riservata, nella sottocartella Json.
Per utilizzare un Json è necessaria la conoscenza della struttura specifica del Json che si vuole trattare. A tal scopo è stato rilasciato un servizio e relativa scheda che permettono la navigazione dei Json, dove la gerarchia delle informazioni è interrogabile nel nostro modo consueto ad albero ed i relativi valori sono visualizzabili in matrice o input/output panel. Lo scopo del servizio è permettere in modo intuitivo di conoscere la struttura di un Json ai fini di un accesso ai dati con le nuove API e di rendere il json immediatamente fruibile in scheda, pertanto avere i relativi attributi caricati in variabili e poterle utilizzare direttamente con dinamismi e bottoni. Sia scheda che servizio si chiamano LOSER_37. Potete cominciare a provare caricando un Json da file in locale, o ancor meglio copiatelo in IFS ed utilizzatelo subito anche con le nuove API che vi andrò poi a descrivere.
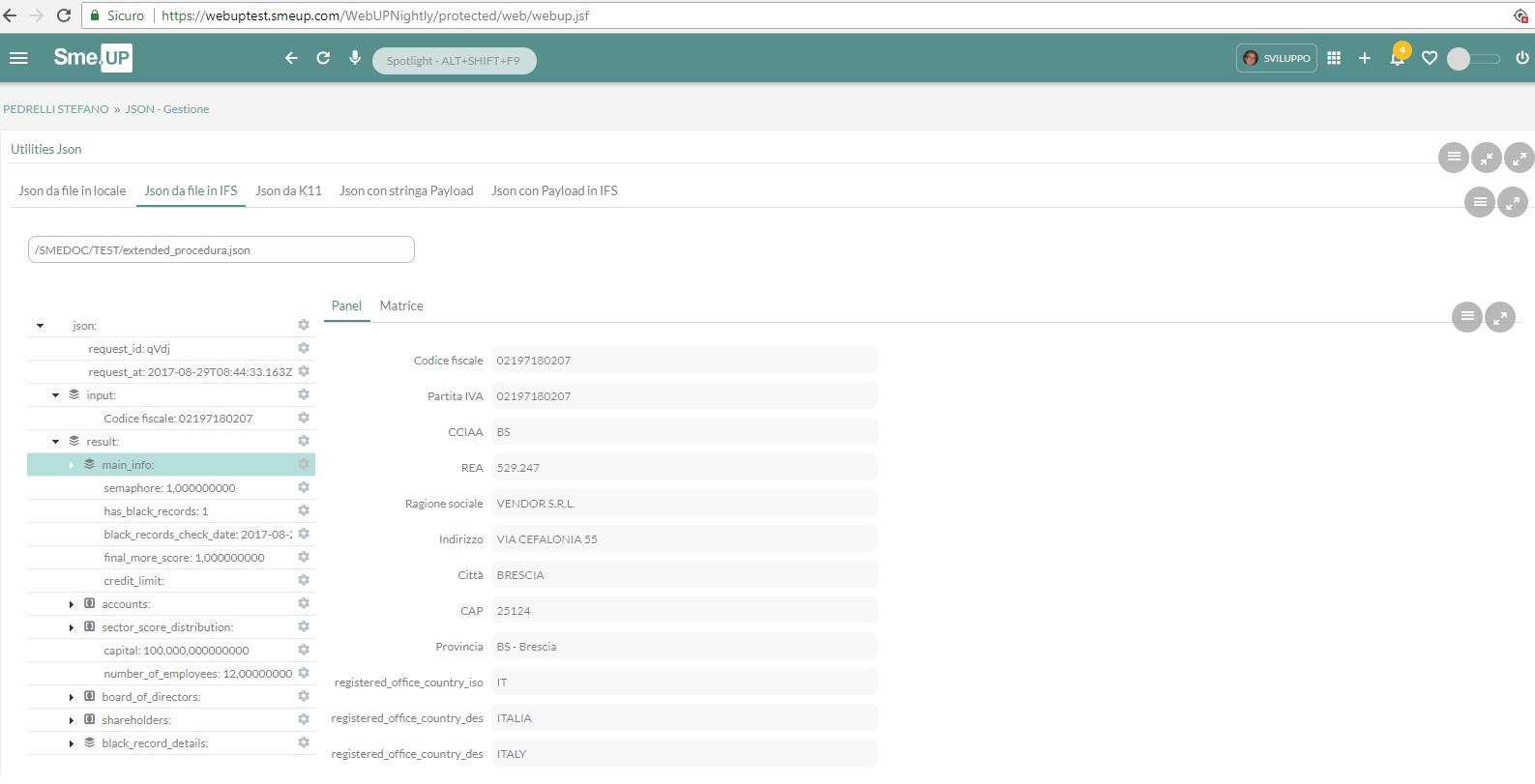
Chi lo vede per la prima volta mi pare sempre stupito per quanto è intuitivo e chi lo usa abitualmente per quanto è potente ed efficace anche con i json più complessi, pertanto non è necessario dire altro su questo motore, sbizzarritevi nella navigazione.
Con tutta probabilità la necessità applicativa prevederà che il Json debba essere reperito on line da un web service, pertanto bisogna conoscere anche come interfacciarsi per la chiamata, per tutto ciò si rimanda a questo articolo: Web Service REST e LOA38
La K37 – l’API di alto livello per la lettura di un Json
Qui comincia la roba per programmatori. Abbiamo rilasciato questa nuova API, che definiamo di alto livello, perchè permette di leggere informazioni da un Json con facilità. Abbiamo rilasciato anche altre nuove API che definiamo di basso livello, perchè rivolte ad un utilizzo più complesso ed elaborativo, soprattutto perchè, per accedere al dato, necessitano di una serie di posizionamenti in memoria agli oggetti che ne definiscono gerarchicamente la struttura. Comunque, avendo la K37, è difficile che ne abbiate bisogno.
La nuova API K37 è estremamente semplice e prevede in input 2 soli parametri, il percorso di un file Json in IFS ed il percorso dell’attributo che si vuole estrarre. Per il momento abbiamo preferito non implementare la possibilità di dare in input il Json all’API da programma, per non demandare al programmatore la complessità ma lasciando all’api la gestione delle problematiche relative alla memoria direttamente da un file IFS, che pertanto può essere anche di grandi dimensioni senza compromettere, anzi ottimizzando le performance.
Le funzioni e metodi sono solo due, GET.ATR per reperire un singolo attributo e CLO per chiudere il Json e liberare la memoria, funzione che è SEMPRE NECESSARIO eseguire al termine della lettura del Json per non lasciare la memoria allocata.
Cominciamo con la lettura del Json prendendo un caso di esempio, che comincia così
{
"request_id": "qVdj",
"request_at": "2017-08-29T08:44:33.163Z",
"input": {
"fiscal_code": "02197180207"
},
"result": {
"main_info": {
"fiscal_code": "02197180207",
"piva": "02197180207",
"cciaa": "BS",
...
Questo è il percorso del file IFS:
/SMEDOC/UNITTEST/extended_procedura.json
Questo è il percorso dell’attributo fiscal_code di cui voglio il valore:
result\main_info\fiscal_code
Pertanto questo è il TST della K37
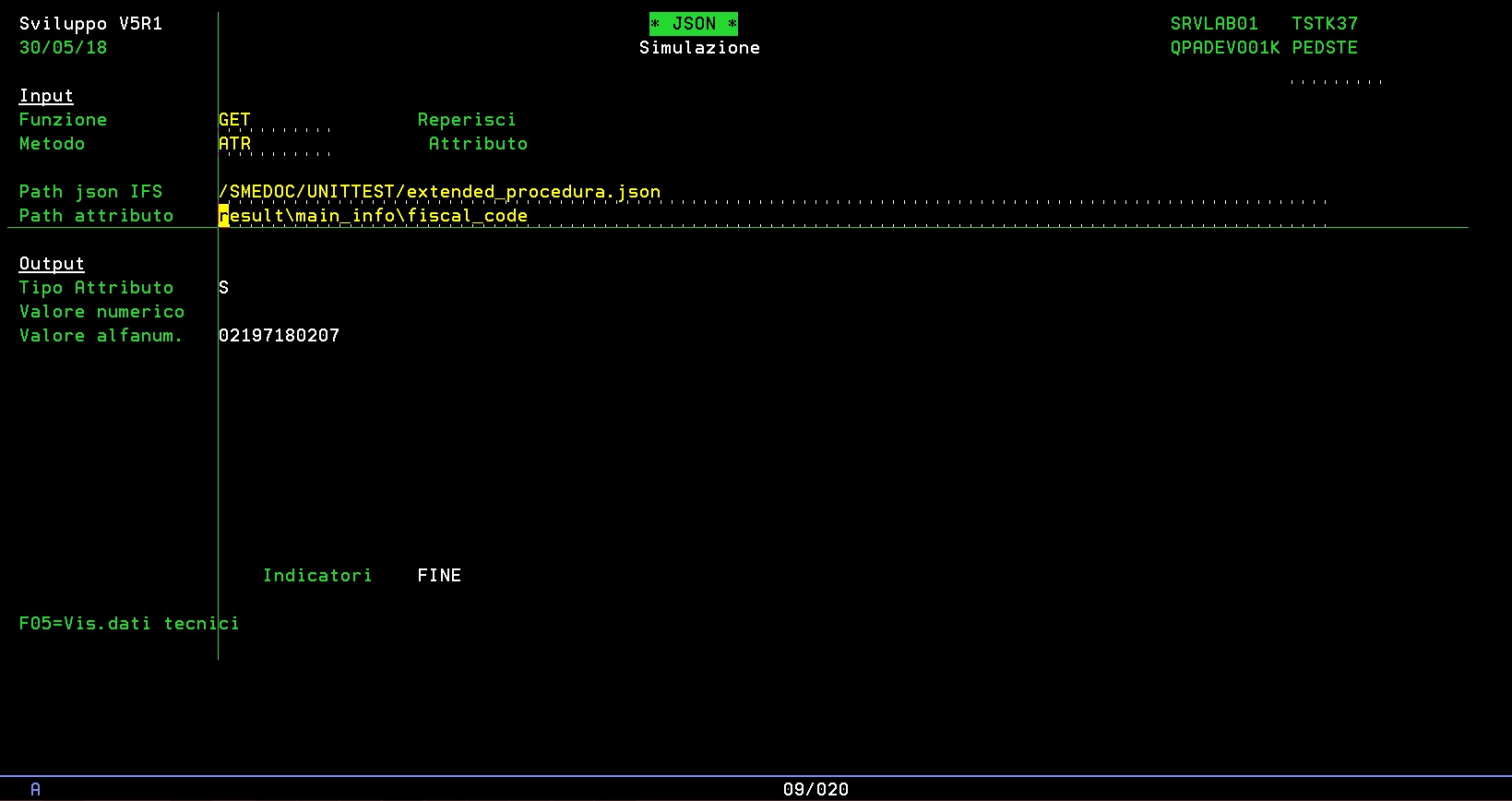
Facile no? Nello specifico, l’API carica il Json in memoria, si posiziona al nodo result, al main_info, all’attributo fiscal_code e ne restituisce il valore. Il tipo attributo indica che è una stringa pertanto ne restituisce il valore alfanumerico, se fosse stato un attributo numerico avrebbe restituito il valore nel campo apposito. E’ bene notare che il messaggio contiene FINE, se contenesse CONT bisognerebbe continuare a leggerne il contenuto, perchè per evitare occupazioni di memoria eccessivi, come in altre APi abbiamo definito che leggiamo al massimo 32000 caratteri alla volta.
Ecco infine un esempio di un array (elenco di valori, anche strutturati, separati da “,” e racchiusi tre “[ ]”). In questo caso è un array di account, dove ogni account ha quattro attiributi:
"accounts": [
{
"closing_date": "2016-12-31",
"months": 12,
"is_consolidated": false,
"account_size": 2
},
{
"closing_date": "2016-02-03",
"months": 1,
"is_consolidated": false,
"account_size": 5
},
...
]
Questo è il percorso dell’attributo is_consolidated di cui voglio il valore:
result\accounts(1)\is_consolidated
Questo è il TST
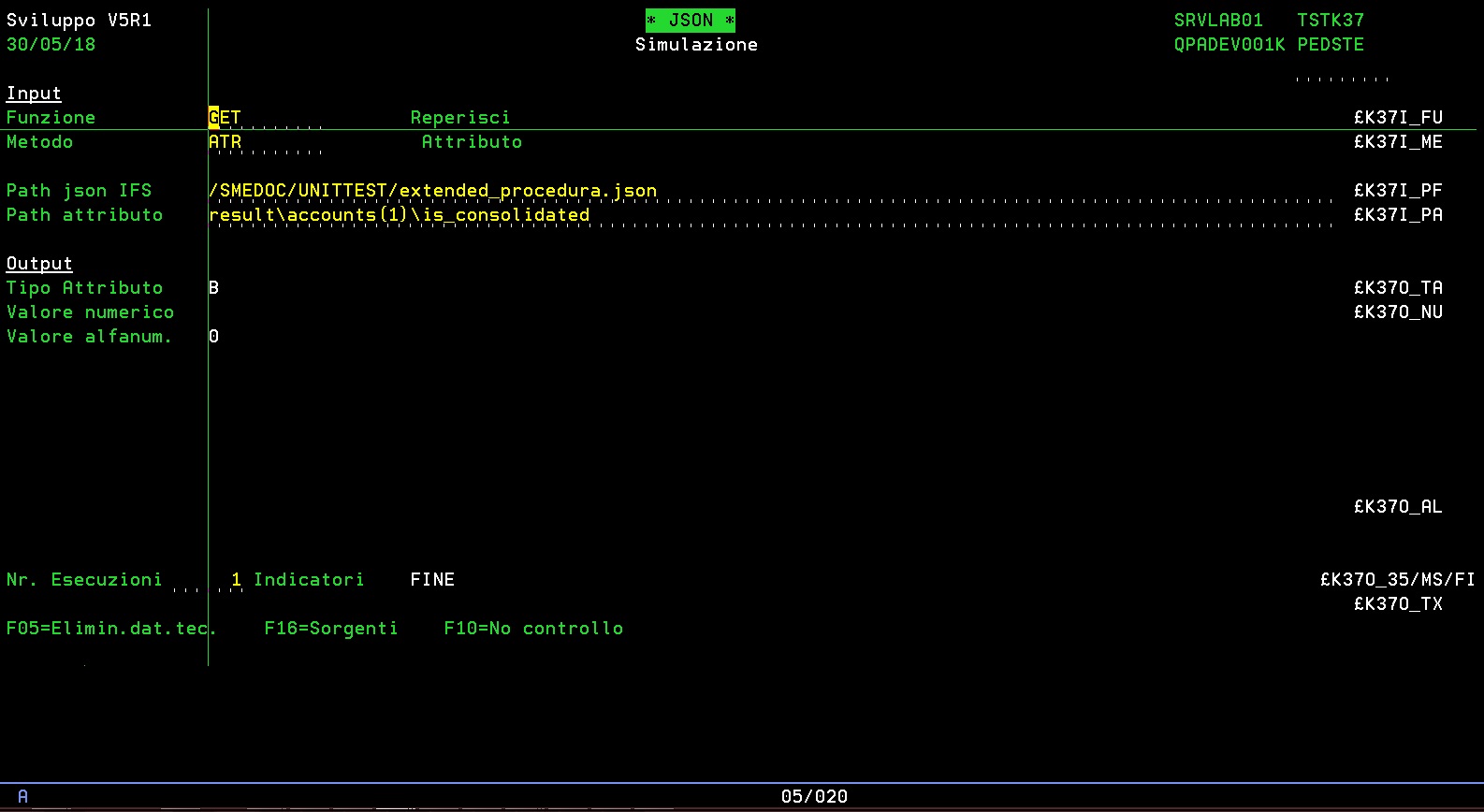
L’elemento dell’array viene indicato tra parentesi, pertanto accounts(1) indica che si richiede il posizionamento al primo elemento dell’array. Il tipo attributo B indica che è un attributo di tipo booleano ed il valore false viene restituito come “0”, true sarebbe “1”.
Tutto qui, bisogna solo ricordarsi sempre alla fine la funzione CLO “Chiudi json”!
Le altre nostre nuove API di basso livello
Qui entriamo nel “difficilotto”. Definiamo queste nuove API di basso livello perchè non hanno la nostra interfaccia tipica a funzioni e metodi come la K37, che restituisce al programma direttamente i valori interessati in variabili, ma sono interfacciate da procedure e bisogna avere almeno una conoscenza di base sui puntatori di memoria in RPGLE, ma se non li avete mai usati è pure un buon modo per cominciare ad averne a che fare.
Cominciamo con il loro utilizzo, il sorgente RPGLE di esempio a cui si riferisce questo articolo è il LOSER_36 che legge un file Json di esempio ed emette una matrice E’ un nostro normalissimo servizio, pertanto mi soffermerò solo sulle procedure specifiche di queste nuove API.
Caricamento del Json ed allocazione della memoria
La prima procedura utilizzata di queste api è la £JSN_FILE_LOAD che carica il file Json contenuto nel percorso IFS nella variabile $PATHF e restituisce il puntatore di memoria in DOCPtr relativo all’area appositamente allocata, l’allocazione viene effettuata direttamente dall’API.
C EVAL $PATHF='/SMEDOC/TEST/extended_procedura.json' C EVAL DOCPtr=£JSN_FILE_LOAD($PATHF:$MSGER:$NODTP)
In alternativa come caricamento del Json è possibile utilizzare la procedura £JSN_BUFF_LOAD passando direttamente il puntatore e la lunghezza dell’area di memoria precedentemente allocata ed in cui è presente il Json precaricato da programma, per esempio da un web service interrogato con la K11. A tal scopo nell’esempio qui sotto al posto della variabile $PATHF idi cui sopra vengono utilizzate le variabili $BUFPTR e $BUFLUN.
C EVAL DOCPtr=£JSN_BUFF_LOAD($BUFPTR:$BUFLUN:$MSGER:$NODTP)
In caso di errore il puntatore è *NULL e la variabile $MSGER contiene una descrizione testuale dell’errore rilevato.
Posizionamento sul nodo
Cominciamo con la lettura del json, quello in esempio è lo stesso della prima immagine di questo articolo
Il posizionamento dei nodi avviene uno alla volta, mi posiziono su uno e poi mi posiziono sul suo figlio, pertanto nel programma di esempio dalla root del documento ci si vuole posizionare sul nodo ‘result’ e viene utilizzata questa procedura, dove RESPtr contierrà il puntatore di memoria al nodo richiesto
C EVAL RESPtr=£JSN_FIND_NODE(DOCPtr:'result':NODTP)
poi dal nodo ‘result’ avviene il posizionamento al nodo figlio ‘main_info’
MAIPtr=£JSN_FIND_NODE(RESPtr:'main_info':NODTP)
Lettura degli attributi
Per recuperare il singolo attributo contenuto nel nodo in cui ci si è posizionati, pertanto per leggerne il valore, bisogna sapere di che tipo di attributo si tratta, può essere stringa, numerico o booleano.
In questo caso si vuole leggere l’attributo ‘fiscal_code’, posizionandosi la variabile NODTP indicherà che è una stringa, pertanto viene utilizzata la procedura £JSN_ATTR_STR
C EVAL ATTPtr=£JSN_FIND_NODE(MAIPtr:'fiscal_code':NODTP) C EVAL VALSTR=£JSN_ATTR_STR(ATTPtr:$RC)
Allo stesso modo è possibile reperire un valore numerico con la £JSN_ATTR_NUM (NODTP=’N’) o un booleano con la £JSN_ATTR_BOL (NODTP=’B’)
C EVAL VALNUM=£JSN_ATTR_NUM(ATTPtr:$RC) C EVAL VALBOL=£JSN_ATTR_BOL(ATTPtr:$RC)
Array
Ecco infine un esempio di un array, l’array è la principale novità del Json rispetto all’Xml
"accounts": [
{
"closing_date": "2016-12-31",
"months": 12,
"is_consolidated": false,
"account_size": 2,
...
Qui il programma di esempio si posiziona sul nodo ‘accounts’ e cicla sugli elementi dell’array in esso contenuti
C EVAL ACCPtr=£JSN_FIND_NODE(RESPtr:'accounts':NODTP) C DO *HIVAL C EVAL ELEPtr=£JSN_LOOP_ARRAY(ACCPtr:i:*IN35:ELETP) C IF *IN35 C LEAVE C ENDIF ...
Una volta posizionati al singolo elemento dell’array è possibile posizionarsi in nodi figli e leggere attributi nelle stesse modalità dai 2 paragrafi precedenti.
C EVAL ATTPtr=£JSN_FIND_NODE(ELEPtr:'is_consolidated':NODTP) C EVAL VALBOL=£JSN_ATTR_BOL(ATTPtr:$RC)
Disallocazione della memoria
Come di consueto al termine dell’utilizzo della memoria allocata con puntatori è necessario disallocarla e questa è la procedura specifica
CALLP £JSN_FILE_FREE(DOCPtr)
Conclusione
Wow, se hai letto fin qui è perchè hai capito tutto anche sulle API di basso livello, allora buon divertimento! 🙂