
Indice articolo
Il machine learning è un sottoinsieme dell’intelligenza artificiale. I modelli/algoritmi di machine learning creano un modello matematico basandosi sui dati storici chiamati training data per fare previsioni o prendere decisioni senza essere esplicitamente programmati.
“Il machine learning è la scienza che dà l’abilità al computer di imparare senza essere esplicitamente programmato.”
Arthur Samuel
Perchè utilizzare il machine learning?
Supponiamo di dover scrivere un filtro spam, se un email è spam o meno;
Con un programma tradizionale prima si dovrebbe:
- Individuare le caratteristiche di ogni spam, per esempio contiene “4U” o “credit card”.
- Scrivere un algoritmo per ognuna di queste caratteristiche.
- Testare il programma, se non va bene ripetere gli steps 1 e 2 fino ad avere un risultato accettabile.
Il programma in questione diventerebbe lungo e complesso.
Un filtro spam basato su machine learning imparerebbe automaticamente le caratteristiche necessarie per la previsione,rilevando pattern inusuali, comparando gli esempi di spam con gli esempi nonspam. Il programma sarebbe più corto e più accurato. Con la programmazione tradizzionale ogni volta che lo spammer cambia un carattere,una parola o frase,
per esempio “4U” con “For U”,
si dovrebbe modificare l’algoritmo di continuo.
Al contrario, per il modello di machine learning basterebbe avere i dati aggiornati e fare il training di un nuovo modello.! Quindi, ora che abbiamo capito la differenza tra programmazione tradizionale e machine learning,
possiamo proseguire con le categorie di machine learning.
Categorie di Machine Learning
Il machine learning si suddivide in 4 categorie:
- Supervised Learning
- Unsupervised Learning
- Semisupervised Learning
- Reinforcement Learning
Supervised Learning
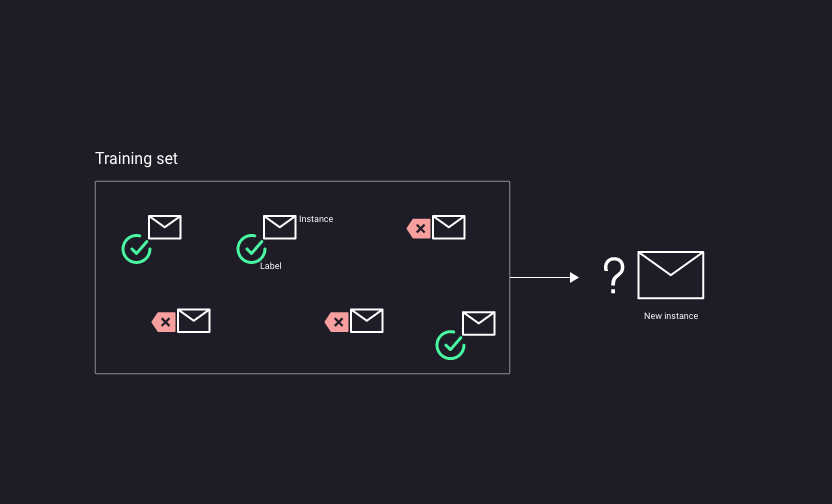
Nel supervised learning i dati che si danno al modello/algoritmo di machine learning contengono
dati di input(Instance) con i rispettivi output(Label).
Questa tipologia di dati viene chiamata labeled data.
Riprendendo l’esempio fatto prima, gli input sono le caratteristiche(frasi, parole, caratteri, etc..) dell’email,
invece l’output è spam o non-spam.
Il supervised learning a sua volta si divide in Classification e Regression.
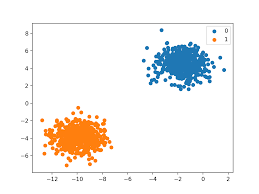
Classification: output binario/categorico(es. [spam o non-spam], [pioggia o soleggiato], etc..) o multiclass(hai più di 2 classi).
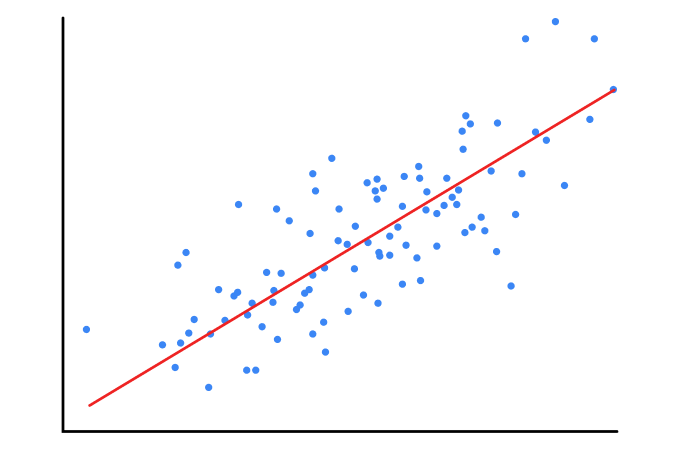
Regression: output continuo( es. valore di una casa).
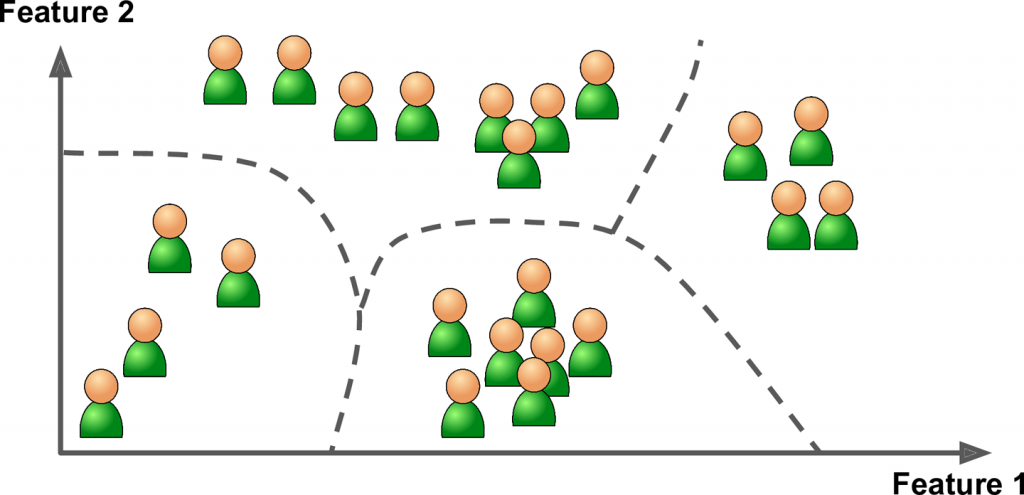
Unsupervised Learning
Nel unsupervised learning i dati che si danno al modello/algoritmo di machine learning contengono solo dati di input, senza output.
Questa tipologia di dati viene chiamata unlabeled data.
In questo caso il modello crea dei cluster/gruppi per separare i dati.
es. separare e ragruppare persone in base al loro genere musicale preferito.
Semisupervised Learning
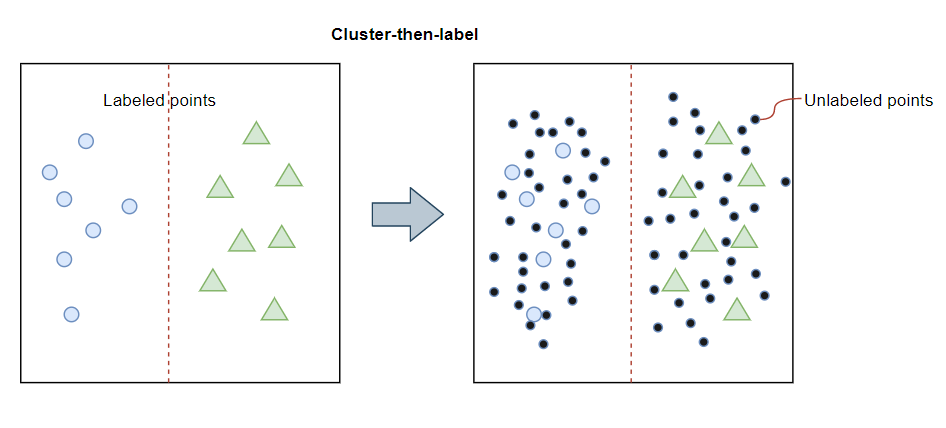
Alcuni modelli/algoritmi possono lavorare con dati parzialmente labeled, cioè nei dati ci sono sia labeled data che unlabeled data,
solitamente tanti unlabeled data ed una piccola precentuale di labeled data.
Questo tipo di modelli/algoritmi viene chiamato semisupervised learning.
Per capire meglio prendiamo come esempio Google Photos.
Dopo aver caricato le foto sul servizzio, google photos riconosce che la persona A è presente nella foto 1,5 e 11,
e la persona B nella foto 2,5 e 7.
Questa è la parte unsupervised dell’algoritmo(clustering).
Dopo di chè l’algoritmo ti chiede chi sono queste persone, il nome che dai a quella persona diventa la label che utilizzerà l’algoritmo per riferirsi alla persona,
basta una label a persona per identificarla in ogni altra foto.
In poche parole usa la piccola percentuale di labeled data per identificare gli unlabeled data.
Reinforcement Learning
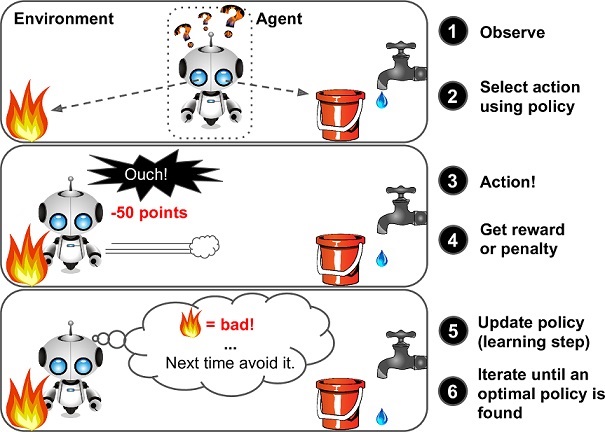
Il reinforcement learning è diverso, il suo sistema di apprendimento è diverso.
In poche parole il modello viene applicato ad un agente che inserito in un ambiente,
seleziona o fa delle azioni e in cambio ottiene delle ricompense se ha fatto l’azione giusta o delle penalità se ha sbagliato.
L’agente impara da solo qual’è la strategia giusta, chiamata policy, per avere il maggior numero di ricompense nel tempo.
La policy definisce quale azione deve scegliere l’agente quando è in una determinata situazione.
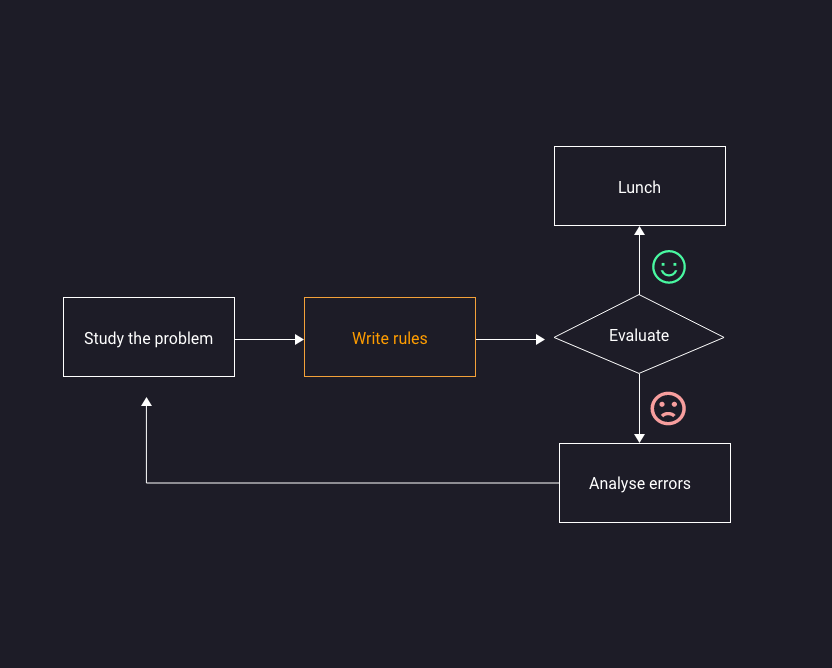
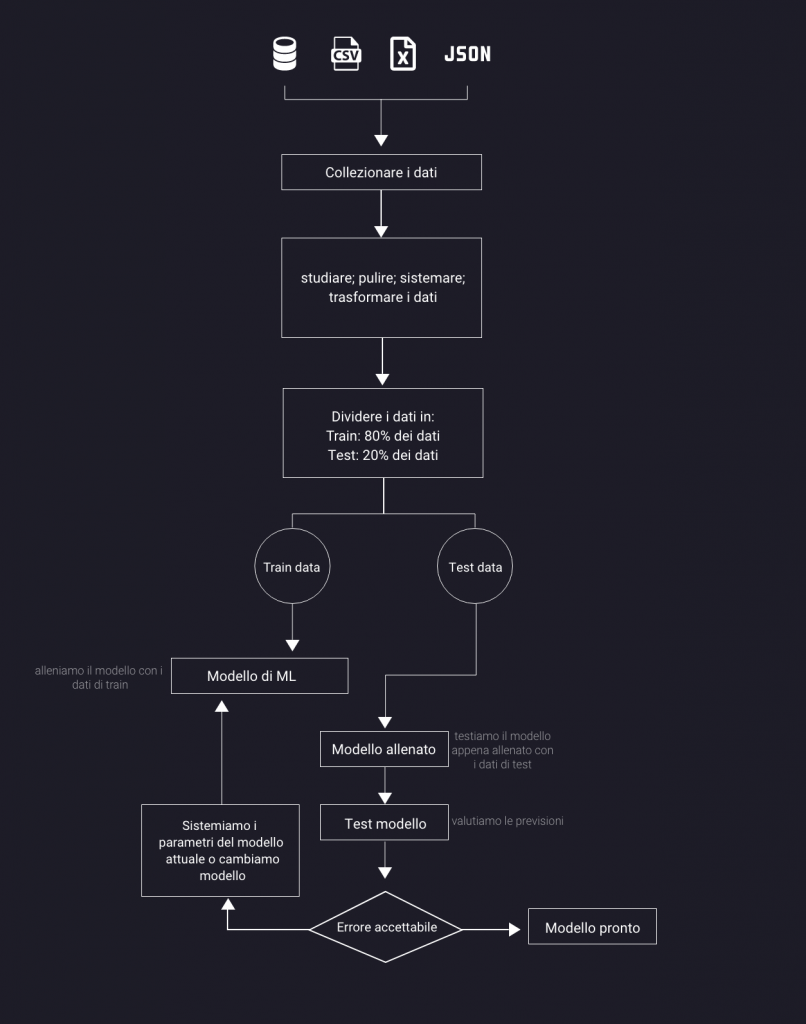
Machine Learning Workflow
Ecco come si svolge un progetto di machine learning (questo diagramma mostra un processo semplificato)
Conclusioni
Il machine learning è un settore in costante crescita, viene utilizzato in molti settori, fra questi ci sono:
- Finanziario
- Healthcare
- Manifatturiero
- Retail
- Trasporto
- Risorse Umane
- Marketing
- Social Media
- Automazione
Il machine learning sta rivoluzionando e facilitando la vita di tutti, é uno strumento che tutti possono utilizzare nel proprio settore.