
Indice articolo
È possibile utilizzare modelli di intelligenza artificiale (AI) di ultima generazione direttamente su IBMi? In questo articolo spiegheremo come il nostro team di sviluppo ha reso vincente il binomio “intelligenza artificiale” + “IBMi“.
In seguito ai vari esperimenti alla scoperta del mondo dell’intelligenza artificiale e dopo averne compreso l’enorme potenzialità, ci siamo chiesti come potessimo integrare queste tecnologie più che mai attuali all’interno del nostro sistema. Il processo di integrazione si è sviluppato principalmente in 2 macro fasi:
- learning/tuning del modello
- realizzazione di una previsione immediata
Learning and tuning
Prima di addentrarci nella spiegazione di questa fase, vorremmo chiarire il concetto che è stato centrale durante tutta l’organizzazione del lavoro, ovvero l’approccio process oriented: in questo contesto si ha un flusso di dati continuamente prodotto dal sistema di partenza (ad esempio da un sistema gestionale) e che deve essere inoltrato ad un servizio esterno (ad esempio un sistema di intelligenza artificiale) in maniera continua, mentre un dato processo è in esecuzione. L’obbiettivo è quello di ottenere dei feedback su tale processo, correggendo eventuali errori e migliorando il modo in cui esso viene eseguito.
Quindi, partendo da un insieme di dati grezzi, si applicano processi di ELT (Extract, Transform, Load) sulle informazioni iniziali per ottenere un dataset adatto alla successiva analisi e creazione del modello di AI.
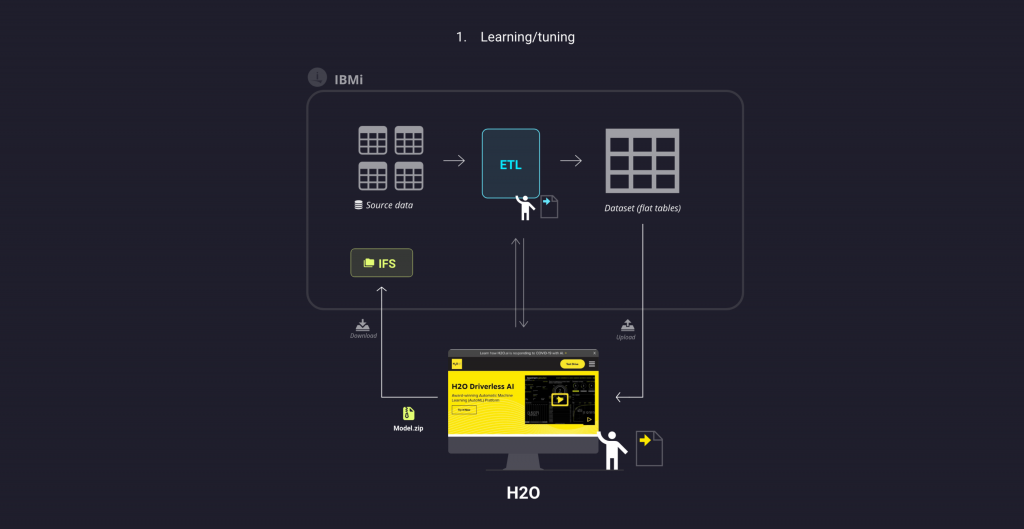
Per la creazione del nostro modello abbiamo scelto h2o.ai, una piattaforma di intelligenza artificiale il cui motto è quello di democratizzare l’AI, nel senso di renderla fruibile ai programmatori ad ogni livello di competenza, e renderla comprensibile anche agli utenti che si approcciano per la prima volta a questo mondo.
Abbiamo quindi realizzato il nostro modello, impostando gli iperparametri più adatti al nostro caso d’uso, e una volta soddisfatti l’abbiamo scaricato e inserito nel nostro sistema, inglobandolo in un programma scritto in linguaggio Python che ne facilitasse l’esecuzione.
Previsione
Conclusa la prima fase, abbiamo poi dovuto pensare a come realizzare il processo di previsione partendo da nuovi dati interni al sistema, in modo da sfruttare il modello precedentemente integrato.
Abbiamo quindi realizzato una UPP, isolabile e distribuibile, composta da alcuni programmi scritti in linguaggi RPG, il cui nucleo è una /copy (ovvero una API) che, ricevendo in input i dati e tramite la valorizzazione di alcune variabili, si occupa di generare la previsione per quei dati dialogando direttamente con il nostro modello. I codici operativi utilizzati all’interno dei programmi sono molto semplici, ma tramite queste istruzioni, il nostro modello riceve i dati e li elabora restituendone una previsione, che viene riportata nel programma e visualizzata in output all’utente che l’ha richiesta. Semplice vero? La complessità delle operazioni sui dati risulta completamente nascosta all’utente finale!
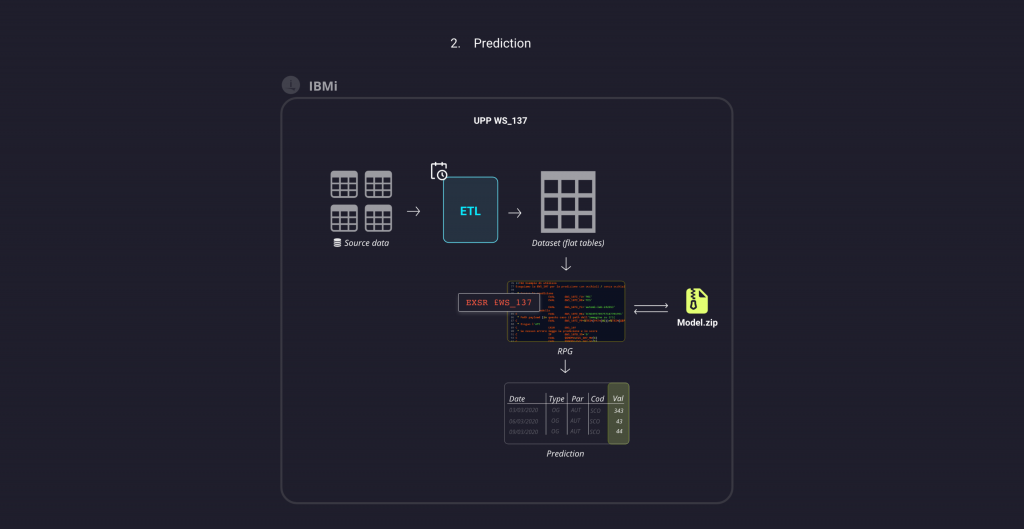
Come avviene dunque la fase di previsione?
Suddividiamo il caso in cui si richiede la previsione su un singolo record dal caso in cui si vuole ottenere una previsione su un insieme di record selezionati che hanno certe caratteristiche comuni.
Inserendo un record che contiene tutte le informazioni necessarie al modello per generare la previsione, si chiama la nostra UPP: il programma centrale riconosce il tipo di dato e si occupa di passare tutte le informazioni necessarie (recuperando eventualmente dal sistema quelle mancanti) al nostro programma Python che a sua volta esegue il modello e genera istantaneamente la previsione. Essa quindi viene riportata in output dal programma, e l’utente visualizza quindi la variabile di cui cercava una previsione con il suo valore predetto dal modello di AI.

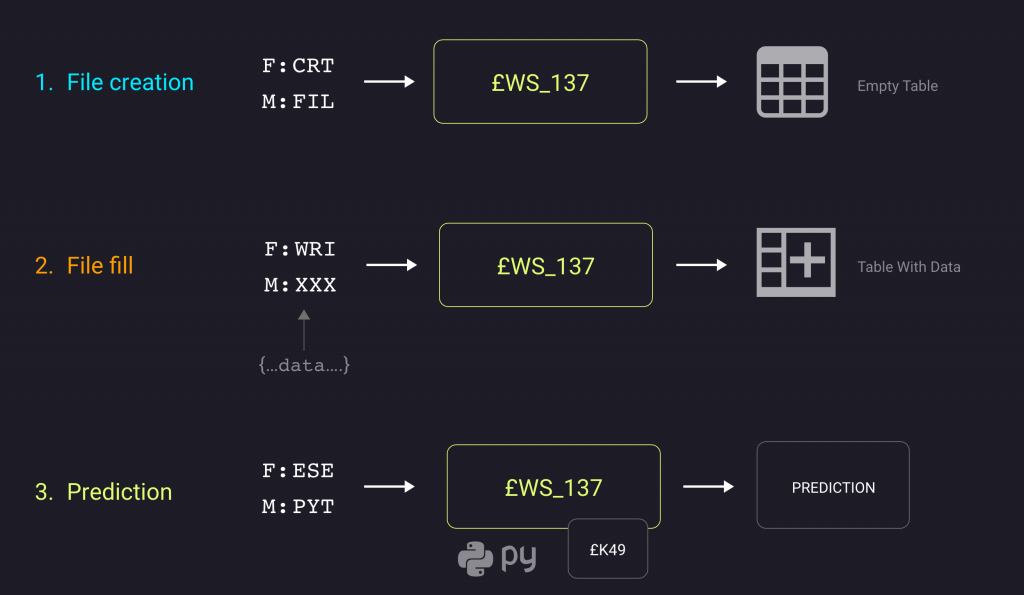
Il funzionamento per record multipli prevede due step intermedi prima della vera e propria previsione: dopo che l’utente ha selezionato l’insieme di record per i quali vuole ottenere l’informazione predetta dal modello, il programma:
- genera uno scheletro del dataset (contenente solo l’intestazione delle colonne) che il modello utilizza per generare la previsione
- popola il file con i record selezionati
Infine, questo dataset viene inviato dal programma al modello, che, analogamente agli step precedenti, effettua una previsione che sarà poi restituita come output all’utente.
Il nostro use case
Abbiamo applicato quanto visto finora ad alcuni dati interni alla nostra azienda: avendo a disposizione alcune informazioni aggiuntive circa la conclusione di una trattativa, volevamo provare a sfruttare l’intelligenza artificiale per ottenere delle previsioni sulla percentuale di successo di una nuova opportunità. Utilizzando h2o.ai, abbiamo quindi realizzato un modello, abbiamo ripetuto le fasi di training e di testing per migliorarlo fino a quando, soddisfatti del risultato, abbiamo ripetuto gli step descritti in questo articolo per integrarlo nel sistema.
Quella che vediamo qui è una schermata dimostrativa di come è possibile ottenere una previsione sulle opportunità, sia su un singolo record che su un insieme di record.
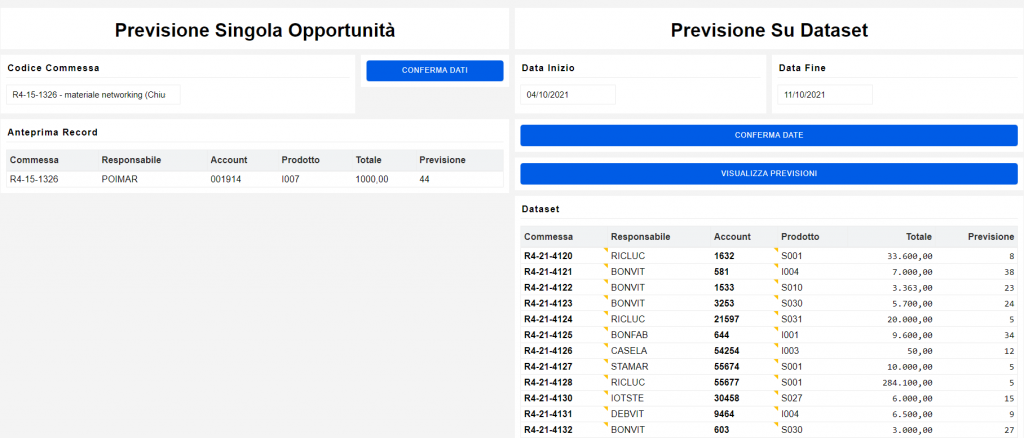
Sulla sinistra concretizziamo lo schema visto per il record singolo: inserendo il codice di una commessa, il sistema recupera in automatico i dati mancanti necessari alla previsione. Quando i dati risultano completi, il programma si occupa di interagire con il modello, eseguendolo per ottenere la percentuale prevista, che viene visualizzata in output nella colonna “Previsione”.
A destra invece viene selezionato un range di date: il sistema recupera le commesse che appartengono a quell’intervallo di tempo con le informazioni necessarie al modello per generare la previsione, secondo lo schema illustrato nel funzionamento con più records. Alla fine, si ottiene la previsione per ogni commessa appartenente al range di date selezionato.
Per vedere la registrazione di questo speech e delle altre pillole, CLICCA QUI.
1 commento su “#h2o.AI on your #IBMi”
Sarebbe estremamente interessante utilizzare questo strumento per esegure delle previsioni commerciali, in modo da confrontare i suoi risultati con quelli dell’algoritmo di Holt Winters, implementato nel nostro prodotto.