
Indice articolo
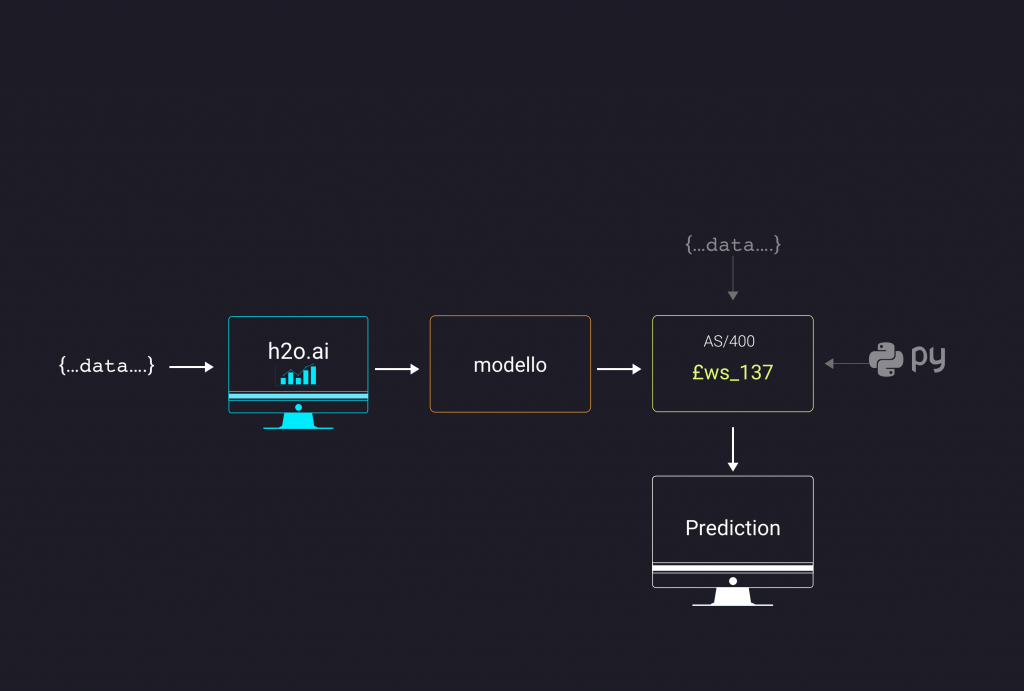
La UPP nasce con l’idea di fondere il mondo Smeup con la piattaforma ibm h2o (https://www.h2o.ai/), al fine di integrare modelli previsionali precedentemente realizzati a seconda dello use case.
Il processo di sviluppo e utilizzo della UPP prevede dunque queste tre fasi:
- Realizzazione del modello in h2o;
- Scrittura del programma python;
- Configurazione della UPP con l’aggiunta del nuovo modello.
Creazione modello h2o
Dato un dataset di riferimento in cui è presente una variabile target da prevedere, h2o assiste l’utente nella creazione di un modello di Machine Learning in grado di effettuare previsioni su nuovi dati con un buon livello di precisione.
Il dataset va caricato su h2o nella sezione “dataset”: dopo che i dati sono resi disponibili su h2o, è possibile visualizzarli grazie a diversi tool grafici per scovare eventuali outliers o dati mancanti. In seguito si divide il dataset in “train” e “test”, impostando la percentuale di split desiderata. Questa divisione è necessaria durante la creazione di un modello per decidere quale percentuale dei dati verrà impiegata per allenare il modello (ovvero cercare di stabilire il miglior algoritmo di calcolo della colonna target) e quale sarà invece destinata a testare la validità del modello per stabilirne l’efficienza.
Passando poi all’opzione “predict” e selezionando la colonna target, h2o riconosce automaticamente se il modello sarà una regressione (ovvero il target è un valore numerico continuo, ad esempio un prezzo) oppure una classificazione (il target è un’insieme di categorie). In seguito è possibile configurare delle opzioni avanzate a seconda dell’esperienza dell’utente, oppure mantenere quelle di default. Infine si sceglie la metrica da utilizzare, che aiuterà a valutare la precisione del modello realizzato.
Una volta creato il modello, è necessario salvarlo in locale per poterlo poi utilizzare nel programma Python e in seguito nella UPP. Il modello non è direttamente fruibile su AS/400, per questo è necessario scrivere un programma Python che verrà poi eseguito nella /copy che supporta la UPP, chiamata £WS_137.
Scrittura del programma Python
Per la scrittura di questo programma si rimanda al video.
Configurazione UPP WS_137 e funzionamento
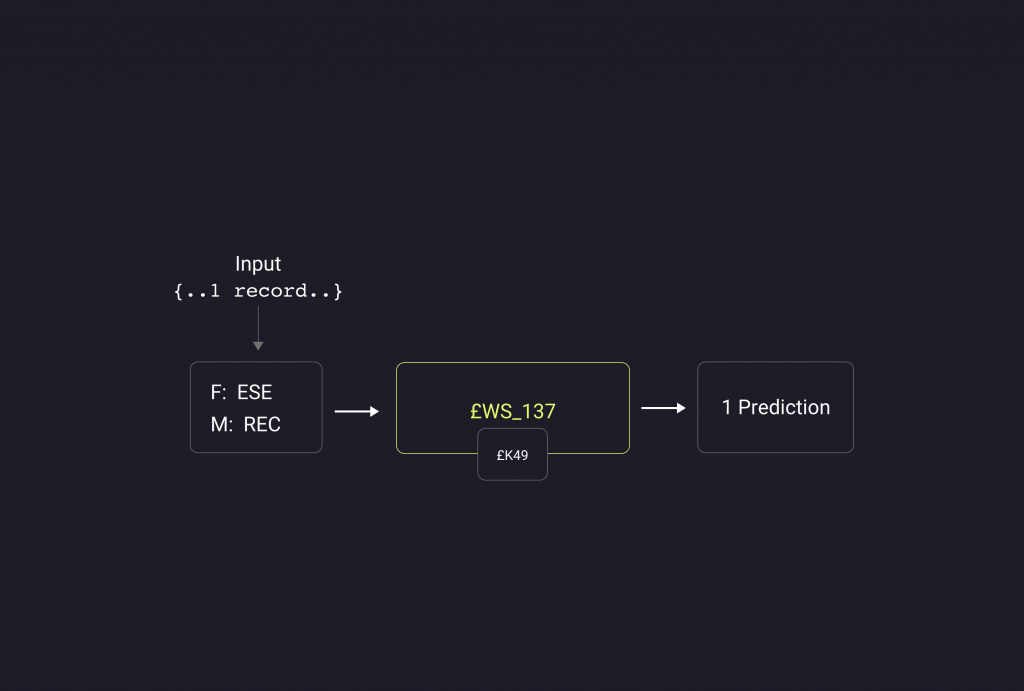
La UPP è stata pensata con una duplice funzione: la previsione su un singolo record e la previsione su un gruppo di record selezionati. Mentre la previsione singola richiede solamente come input il record per il quale si vuole effettuare la previsione, per il caso su più record è necessario ricreare su AS/400 un dataset specifico contenente i nuovi dati da prevedere. Per questo la /copy £WS_137, predispone la funzione di creazione e scrittura record, da eseguire prima di lanciare la previsione massiva.
Nel dettaglio:
- Previsione singolo record -> occorre un’unica chiamata alla copy con funzione ESE e metodo REC, inserendo nell’input il record. La copy a sua volta chiama la £K49 per lanciare il comando che eseguirà il programma Python scritto in precedenza e allocato nel file system.
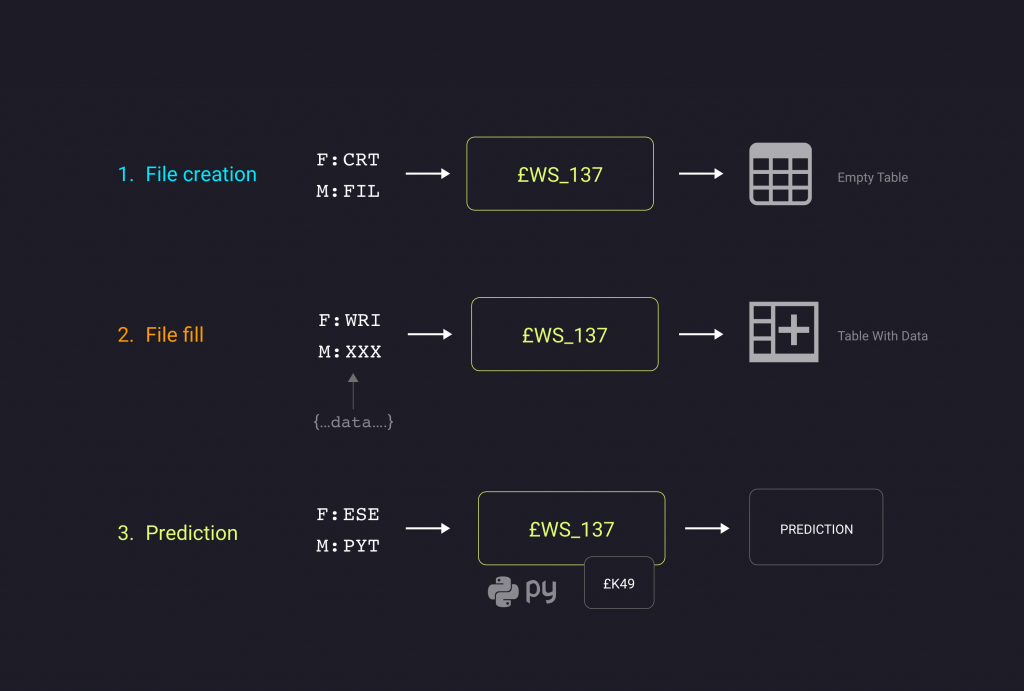
- Previsione gruppo di record -> In questo caso occorrono tre diverse chiamate alla /copy:
- Creazione del file con le sole colonne intestate, utilizzando la funzione CRT con metodo FIL. Il file viene creato in QTEMP tramite la £CKO per evitare che più persone contemporaneamente trattino lo stesso file presente su AS/400.
- Popolamento con i record, che vanno indicati singolarmente nell’input con funzione e metodo valorizzati rispettivamente con WRI e XXX dove XXX è il nome del file creato precedentemente.
- Previsione, specificando la funzione ESE e metodo PYT. Durante l’esecuzione, i record scritti precedentemente vengono riscritti in csv dalla £G80 per poi passarli al file pyhton che esegue la previsione utilizzando il modello di h2o. Come nel caso della previsione singola, la copy utilizza la £K49 per lanciare il programma python contenente il modello da eseguire.
Esempio di applicazione: previsione percentuale conclusione commesse
La UPP è stata utilizzata su dati interni con l’obiettivo di prevedere la percentuale di riuscita di una commessa. Sulla base di alcune informazioni tra cui il responsabile affidato alla commessa e il prezzo, la previsione rappresenta la probabilità di buona riuscita della trattativa. L’esempio è reso disponibile selezionando il modello “opportunità” dalla scheda previsioni della UPP WS_137, in cui è possibile scegliere la previsione singola, inserendo il codice di una commessa, oppure la previsione massiva, selezionando il range di date per il quale si vuole ottenere la previsione.
Conclusioni
L’obbiettivo del progetto è stato dunque quello di integrare modelli di Machine Learning e renderli fruibili anche all’interno di Smeup. Speriamo che questo progetto sia stato utile per capire le enormi potenzialità dell’intelligenza artificiale e di come essa possa avere infinite applicazioni nella nostra quotidianità, e che questo articolo sia risultato interessante ed esaustivo nel caso in cui si desideri creare un modello previsionale in h2O ed utilizzarlo per effettuare delle previsioni tramite la UPP WS_137 – Integrazione h2O.
2 commenti su “UPP WS_137 – INTEGRAZIONE H2O”
complimenti: questa è innovazione e va trasferita alla forza vendita, deve diventare un plus della nostra offerta
il tema è molto interessante, ma l’articolo è troppo tecnico e quindi non riesce a divulgare agli usufruitori del’intelligenza artificiale che sono più interessati a come debbono essere i dati da produrre e come è fatto l’output.