
Indice articolo
All’interno di Smeup, un ticket è una segnalazione che un cliente o un operatore del settore delivery può fare, riguardante un errore all’interno di un prodotto Smeup. Una volta ricevuto il ticket c’è qualcuno che lo assegna ad un solver per gestirlo e risolverlo: abbiamo fatto dei piccoli esperimenti per provare a testare un’eventuale gestione non manuale del processo, appoggiandoci al Machine Learning. In questo articolo illustreremo i risultati ottenuti.
Lo scopo di questo esperiemento è quello di automatizzare l’assegnazione di un ticket ad un solver. Bisogna quindi prima di tutto affidarsi ad una piattaforma che offre servizi di machine learning.
Inizialmente ci si era appoggiati ad H2O.ai ma il modello costruito produceva una percentuale di accuratezza relativamente bassa (attorno al 30%).
Abbiamo quindi deciso di provare la piattaforma Microsoft Azure.
Per giungere ad una soluzione si è pensato di seguire questi passaggi:
- Analisi del file ticket.csv;
- Pulizia della colonna ‘Testo segnalazione’ contenente il messaggio e l’eventuale problema;
- Assegnare ad ogni risolutore una categoria. Le categorie scelte sono: AS400/Server, Provider Gateway, WebUp e LoocUp;
- Tramite AutoML, uno strumento fornito da Azure, cercare di capire il miglior algoritmo da utilizzare;
- Creare una pipeline e nello specifico effettuare il train del modello e testare l’attendibilità dei risultati.
1. Analisi del file ticket.csv
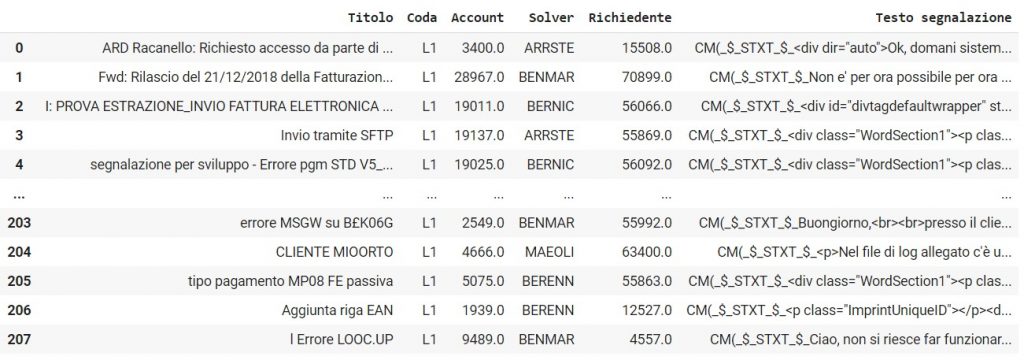
Il dataset è strutturato in 6 colonne:
- Titolo: oggetto della mail
- Coda: a noi interessa solo la coda L1 in quanto è quella inerente all’ambito dello sviluppo
- Account: codice aziendale
- Solver: risolutore effettivo del ticket
- Richiedente: persona dell’azienda che ha inviato il ticket
- Testo segnalazione: Contiene il codice HTML della mail che sostanzialmente è il ticket
2. Pulizia colonna ‘testo segnalazione’
Il cuore del progetto. Per garantire il miglior risultato è necessario ottenere un testo segnalazione pulito e contenente solo le informazioni principali e utili. Inizialmente il testo segnalazione non è altro che un codice HTML contente tag e altri caratteri speciali.
Dunque il primo passo sta nel rimuovere questi caratteri e tag tramite espressioni regolari.
Successivamente bisogna rimuovere tutti i link e numeri in quanto poco utili. Infine è necessario cercare di ridurre al minimo il testo lasciando solo le informazioni utili. Questo processo è detto NLP (Natural Language Processing), infatti l’NLP è in grado di dare ai computer la capacità di comprendere il testo più o meno allo stesso modo degli esseri umani.
Per fare ciò serve seguire degli step:
- Dividere il testo in frasi
- Tokenizzare le parole di una frase. Ovvero separare ogni parola all’interno di una frase
- Lemmatizzazione del testo: ridurre ogni parola alla sua forma base
- Identificare e rimuovere le stopwords: vengono rimosse quelle parole che appaiono frequentemente e non danno significato al testo (e,o,è,ha,…)


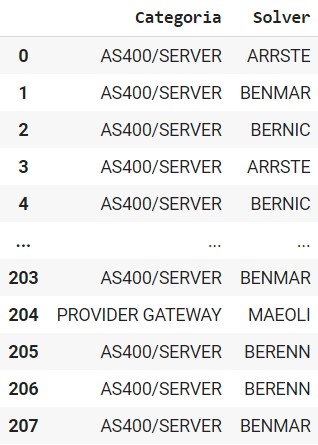
3. Assegnare ad ogni risolutore una categoria
In questo passaggio va creata una colonna categoria. Di base abbiamo creato 4 categorie: AS400/Server, Provider Gateway, WebUp e LoocUp. Abbiamo identificato queste categorie come le principali e abbiamo assegnato ogni solver ad una di queste categorie (Es. BENMAR avrà come categoria AS400/SERVER). Questo passaggio è fondamentale per effettuare il train del modello e aiutarlo a classificare ogni ticket con una categoria.
4. AutoML per il miglior modello
Machine Learning automatizzato, o Auto ML, è il processo che consente di automatizzare le attività iterative per lo sviluppo di modelli di Machine Learning. Da alcuni primi test sul nostro dataset è risultato che il modello StandardScalerWrapper, LogisticRegression ha un’accuratezza del 51%.
5. Creazione Pipeline
Come step finale ci siamo occupati di creare un modello di machine learning. Abbiamo fatto questo tramite la finestra di progettazione, uno strumento fornito da Azure che consente di connettere in modo visivo set di dati e moduli in un pannello Canvas interattivo per creare modelli di Machine Learning.
Il risultato ottenuto è il seguente:
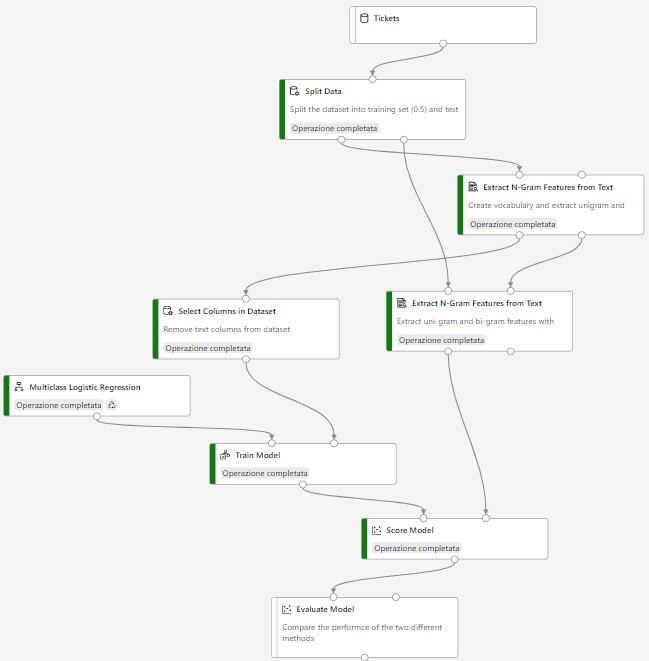
L’algoritmo utilizzato è il “Multiclass Logistic Regression” che ha prodotto i seguenti risultati:
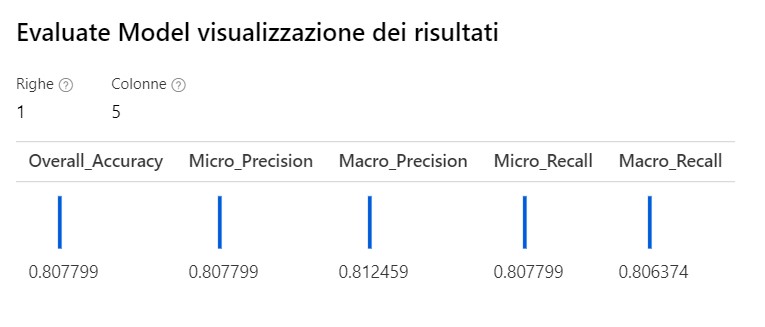
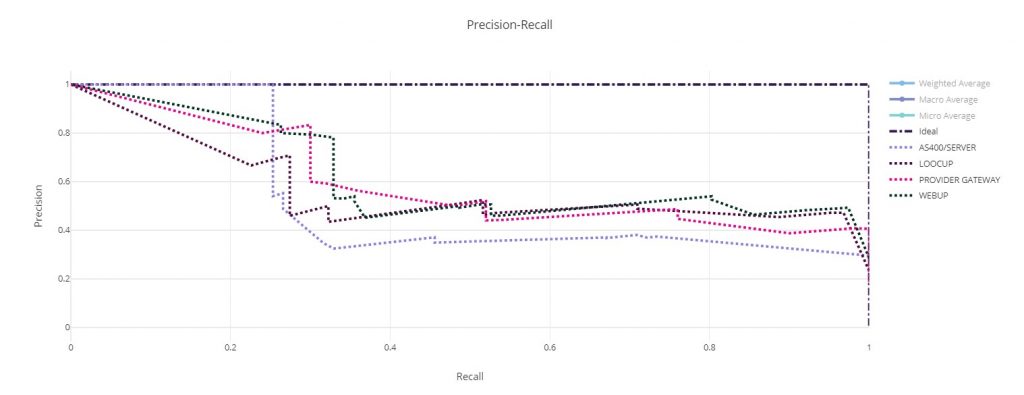
Come possiamo notare questo modello ha un’accuratezza finale dell’80%, di gran lunga più precisa rispetto a quella ottenuta su H2O.ai.
8 commenti su “Gestione dei ticket con Azure Machine Learning”
Cosa rappresentano e come si calcolano i 5 parametri finali di classificazione?
Grazie
I 5 parametri finali sono delle metriche che consentono di valutare l’efficienza del modello. In particolare:
– Overall accuracy rappresenta la probabilità che un input nuovo sia classificato correttamente, e viene calcolato come (somma dei casi classificati correttamente)/(somma di tutti i casi presenti);
– Precision (micro e macro) rappresenta il rapporto tra il numero delle previsioni corrette di un evento sul totale delle volte che il modello lo prevede. In particolare poi, quando il modello è multiclasse (ovvero l’input deve essere classificato dal modello in più di due classi), come nel nostro caso, micro e macro diversificano il modo in cui la precisione viene calcolata sulle varie classi. La micro aggrega i contributi di ogni classe per fare una precisione media totale, invece la macro calcola la precisione in modo indipendente per ogni classe e poi fa una media.
– Recall (micro e macro) misura la sensibilità del modello, e si calcola facendo il rapporto tra le previsioni corrette per una classe e il totale dei casi in cui si verifica effettivamente. La distinzione tra micro e macro è la stessa della metrica precision.
Scusa un’altra domanda.
Il risultato è assegnare al ticke una categoria oppure anche un solver? In quest’ultimo caso vengono fatte considerazioni di bilanciamento di carico tra i solver? Se sì, sarebbe un inizio di schedulazione grezza.
Il risultato assegna il ticket ad una classe, non ad un solver. Ci è sembrato un modo di semplificare il problema, almeno per iniziare.
Ancora una cosa
non ho trovato l’output tokenizzato
Avete capito come mai l’accuratezza di AutoML è superiore a quella di H2O?
Non capisco come funziona la previsione e come è stato fatto il dataset. Cosa è che il modello prevede? Cerca di capire dal testo la categoria da cui desume il solver oppure fa qualcosa d’altro?
Sia AutoML che h2o forniscono un servizio di intelligenza artificale “automatizzata”. Questo significa che sono quasi dei contenitori a scatola chiusa, non è possibile avere un controllo approfondito degli algoritmi utilizzati nel processo di training. Ognuna delle due piattaforme crea la propria personalizzazione degli algoritmi utilizzati per ogni gruppo di applicazione del ML (ad esempio avremo algoritmi leggermente diversi per quanto riguarda l’analisi del linguaggio naturale (NLP)).
Il dataset è stato modificato prima di essere caricato ed utilizzato dal modello, e la sua forma al momento del caricamento utilizza solo 5 colonne: Account, Categoria, Richiedente, Titolo e Testo segnalazione. La colonna “testo segnalazione” è stata ripulita tokenizzata come appare nell’immagine del relativo paragrafo. Il modello cerca quindi di capire dal testo la categoria, e quindi classifica il ticket nella categoria AS400, Webup, ecc..
Pardon AutoML lo ho utilizzato impropriamente, mi riferivo ad Azure…